目录
---------
本笔记大部分来自 rust 圣经,笔者进行了一部分简化和自己的理解
表达式和语句
Rust 中,表达式会进行求值,然后返回一个值,例如 5 + 6 的返回值是 11,因此它也是表达式
利用表达式,可以做到其他语言无法实现的东西:
fn main() {
let y = {
let x = 3;
x + 1 // 这里如果加 ;那么就是语句了
}
println!(y); // 4
}
而语句会执行一些操作,但是不会返回值,例如:
fn sum_num(x: i32, y: i32) {
let x = x + 1; // 语句
let y = y + 5; // 语句
x + y // 表达式
}
函数
rust 的函数大致结构:
fn add_sum(i: i32, j: i32) -> i32 {
i + j
}
看起来很简单,但是 rust 函数要求有以下几点:
- 函数名和变量名以蛇形命名法(snake case),例如上述是
add_sum而不是addSum - 函数位置和
js的 function 一样,会有变量提升 - 每个参数都需要标注类型
特殊返回类型
- 函数没有返回值
rust 中,如果函数没有返回值,会默认返回一个零长度的元组 ()
例如下面的 report 函数隐式返回了一个 ():
use std::fmt::Debug;
fn report<T: Debug>(item: T) {
println!("{:?}", T);
}
显示的返回 ():
fn clear(text: &mut String) -> () {
*text = String::from("")
}
发散函数
永不返回!,当时用 ! 作为返回类型的时候,表示该函数永不反回,可以用来作为程序崩溃的函数,例如:
fn exit_end() -> ! {
panic("end of road!");
}
或者无限循环,因为循环永远不跳出,因此函数也永不反回!
fn forever() -> ! {
loop {
// ...
};
}
所有权
理解所有权之前,我们需要了解堆和栈的区别:
-
栈
栈按照顺序存储值并以相反顺序取出值,遵循先进后出的原则,增加数据叫做进栈,移除数据叫做出栈
-
堆
对于大小未知或者可能变化的数据,是存放在堆上的,当向堆上放入数据时,需要请求内存空间。操作系统在堆的某处找到一块足够大的空位,标记为已使用,并返回一个表示该位置地址的指针,该过程叫做在堆上分配内存。
接着,该指针会被推入栈中,后续使用过程中,通过指针获取数据在堆上的实际内存位置。
由上可知,堆是一种缺乏组织的的数据结构,因此入栈是比堆上分配内存快的多,因为入栈时操作系统无需分配新的空间,只需要将数据放入栈顶即可。
同时,借助 CPU 高速缓存,读取速度方面,栈可以比堆的访问速度块 10 倍以上(栈数据可以存储在 CPU 高速缓存中,而对数据只能存储在内存中)
跟踪堆上的数据何时分配和释放是非常重要的,否则会产生内存泄漏,rust 的所有权就是为了更加安全的使用堆数据。
所有权原则
- Rust 中每一个值都被一个变量所拥有,改变量被称为值的所有者
- 一个值同时只能被一个变量所拥有,或者说一个值只能有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
变量作用域
和大多数语言一样,变量是具有作用域的,例如:
{
let s = "hello"; // s 声明后开始有效
} // 作用域结束,s 不再有效
数据交互
先看两个类似的代码:
let x = 5;
let y = x;
println!(x);
let s1 = String::from("hello");
let s2 = s1;
println!"{}", s1);
虽然两者十分类似,但是第二段代码编译会出问题的,因为 String 类型是分配在堆中的,我们将 s1 的所有权转让给了 s2,此时 rust drop 掉了 s1,s2 是无效引用。
第一段代码不会报错,是因为整数是基本类型,都被存放在栈中,将 x 赋值给 y,便是进栈的过程。
再来看另一段代码:
fn main() {
let x = "hello world";
let y = x;
println!("{}, {}", x, y);
}
这段代码却不会报错,是因为 x 的类型是 &str,只是存储在二进制的字符串 "hello world",并没有持有所有权
深拷贝
rust 永远不会自动创建数据的“深拷贝”,但是如果我们确实需要 String 堆上的数据,而不仅仅是站上的数据,可以使用一个叫做 clone 的方法:
let s1 = String::from("hello");
let s2 = s1.clone();
println!"s1 = {}, s2 = {}", s1, s2);
浅拷贝
浅拷贝只发生在栈上,因此性能更好,例如:
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);
这样既产生了类似深拷贝的效果,也没有报所有权的错误,原因是像整数类型在编译时是已知大小的,会被存放在栈上。
另外,rust 有一个叫做 Copy 的特征,可以用在类似整型这样在栈中存储的类型,如果一个类型拥有 Copy 特征,一个旧的变量在被赋值给其他变量后仍然可用,判断变量是否具有 Copy 特征的通用规则:
任何基本类型的组合可以 Copy ,不需要分配内存或某种形式资源的类型是可以 Copy 的。如下是一些 Copy 的类型:
- 所有整数类型,比如
u32 - 布尔类型,
bool,它的值是true和false - 所有浮点数类型,比如
f64 - 字符类型,
char - 元组,当且仅当其包含的类型也都是
Copy的时候。比如,(i32, i32)是Copy的,但(i32, String)就不是 - 不可变引用
&T,例如转移所有权中的最后一个例子,但是注意: 可变引用&mut T是不可以 Copy的
函数传值与返回
将变量传递给函数一样会发生所有权的转移,或者赋值,例如:
fn main() {
let s = String::from("hello");
takes_ownship(s); // s 的值移动到函数里
// s 不再有效
let x = 5;
makes_copy(x); // x 移动到这个函数里
// i32 是可 Copy 的,所以 x 继续有效
}
fn take_ownship(str: String) {
println!("{}", str);
} // str 移除作用域,drop 掉其占用的内存
fn makes_copy(interger: i32) {
println!("{}", interger);
} // interger 移除作用域
同样,函数返回值也有所有权:
fn main() {
let s1 = gives_ownership(); // gives_ownership 将返回值
// 移给 s1
let s2 = String::from("hello"); // s2 进入作用域
let s3 = takes_and_gives_back(s2); // s2 被移动到
// takes_and_gives_back 中,
// 它也将返回值移给 s3
} // 这里, s3 移出作用域并被丢弃。s2 也移出作用域,但已被移走,
// 所以什么也不会发生。s1 移出作用域并被丢弃
fn gives_ownership() -> String { // gives_ownership 将返回值移动给
// 调用它的函数
let some_string = String::from("hello"); // some_string 进入作用域.
some_string // 返回 some_string 并移出给调用的函数
}
// takes_and_gives_back 将传入字符串并返回该值
fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域
a_string // 返回 a_string 并移出给调用的函数
}
引用和借用
由于 rust 的所有权的特性,仅仅通过转移所有权方式获取值,会让程序变得十分复杂,如果需要获取某个变量的指针或者引用,可以通过 借用(Borrowing) 来实现,获取变量的引用,称之为借用
引用与解引用
常规引用是一个指针类型,指向对象存储的内存地址,和 c 语言指针操作基本一致:
fn main() {
let x = 5;
// y 是 x 的一个引用
let y = &x;
assert_eq!(5, x);
// *y 便是解引用
assett_eq!(5, *y);
}
不可变引用
我们可以通过引用的方式,不转移所有权
fn main() {
let s1 = String::from("hello");
// 通过 &s1 引用的方式,不转移 s1 的所有权
let len = cal_len(&s1);
// s1 还可以继续使用
}
// 引用类型,需要在类型前加 &
fn cal_len(s: &String) -> usize {
s.len()
}
&符号即是引用,允许我们只使用值,而不获取所有权
可变引用
不可变引用是无法修改的,例如以下代码会报错:
fn main() {
let s1 = String::from("hello");
// 通过 &s1 引用的方式,不转移 s1 的所有权
let len = change_str(&s1);
// s1 还可以继续使用
}
// 引用类型,需要在类型前加 &
fn change_str(s: &String) {
s.push_str("world");
}
我们只需要几个小调整,就可以修正错误:
- 声明可变类型,关键字:
let mut; - 创建可变引用,例如:
&mut s1; - 修改函数参数为可变引用类型,例如
s1: &mut String
fn main() {
let mut s1 = String::from("hello");
// 通过 &s1 引用的方式,不转移 s1 的所有权
let len = change_str(&mut s1);
// s1 还可以继续使用
}
// 引用类型,需要在类型前加 &
fn change_str(s: &mut String) {
s.push_str("world");
}
注意点
- 可变引用同时只能存在一个
同一个作用域,特定数据只能有一个可变引用,例如以下代码是错误的:
let mut s = String::from("hello");
let s1 = &mut s;
let s2 = &mut s;
println!("{}, {}", s1, s2);
这种限制的好处使得 rus 在编译器就避免数据竞争
- 可变引用和不可变引用不能同时存在
这句话很好理解,不可变引用正在借用数据,突然被一个可变引用修改值了,那肯定是不合理的,例如以下错误代码:
let mut s = String::from("hello");
let r1 = &s; // 没问题
let r2 = &s; // 没问题
let r3 = &mut s; // 大问题
println!("{}, {}, and {}", r1, r2, r3);
不过随着 rust 的编译器优化,以下代码在新的编译器是可以通过的:
fn main() {
let mut s = String::from("hello");
let r1 = &s;
let r2 = &s;
println!("{} and {}", r1, r2);
// 新编译器中,r1,r2作用域在这里结束
let r3 = &mut s;
println!("{}", r3);
} // 老编译器中,r1、r2、r3作用域在这里结束
// 新编译器中,r3作用域在这里结束
悬垂引用
悬垂引用(Dangling References)也叫做悬垂指针,意思是指针指向某个值后,这个值被释放掉了,而指针仍然存在:
fn main() {
let ref_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}
借用规则总结
- 同一时刻,你只能拥有要么一个可变引用, 要么任意多个不可变引用
- 引用必须总是有效的
元组
元组是由多种类型组合到一起形成的,元组的长度和其中的元素顺序都是固定的,例如:
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}
解构赋值
和 js 一样,rust 也可以使用解构赋值,不同的是:元组使用的是 () 小括号解构
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
let (x, y, z) = tup;
}
访问元素
元组可以通过 . 运算符访问元素:
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
let first = tup.0;
let second = tup.1;
}
单元类型
单元类型就是 (),虽然看起来没啥用,但是 main 函数的返回值就是单元类型 (),发散函数的返回值也是 (),常见的例如 println! 的返回值也是 ()
还可以用 () 作为 map 的值,表示我们不关注具体的值,只关注 key
字符串
rust 中的字符串和其他语言差异很大,有两种类型:&str 和 String,其中:
&str是静态字符串,一旦定义,字符串不会被修改String类型是动态字符串,也可修改
同时,两种类型并不相融,例如以下报错代码:
fn main() {
// name 的类型是 &str
let name = "hello world";
greet(name);
}
fn greet(s: String) {
println!("你好, {}", s);
}
将 String 类型转为 &str 类型,只需要取引用即可,以下三个方法效果相同:
let s = String:from("hello, world!");
let str = &s;
let str = &s[..];
let str = s.as_str();
字符串索引
在其他语言中,通过索引去访问字符串的某个字符或者字串是很正常的行为,但在 rust 中不允许,例如以下错误代码:
let s1 = String::from("hello");
let h = s1[0];
这是因为在 rust 中,字符串的底层数据格式是 [u8],一个字节数组,对于英文来说,一个字母在 utf-8 中仅占一个字节,而对于中文来说占了三个字节
还有一个原因导致 rust 不允许使用索引字符串,因为索引操作我们期望他的时间复杂度是 O(1),但对于 String 类型来说,时间复杂度无法保证
切片
切片允许 rust 引用集合中部分连续的元素序列,而不是整个集合:
let s = String::from("hello world");
let hello = &s[0..5]; // 可省略为 &s[..5]
let world = &s[6..11]; // 可省略为 &s[6..]
如果我们想要截取完整的 String 切片:
let s = String::from("helo");
let len = s.len();
let full = &s[0..len];
let full = &s[..]
对字符串使用切片时要小心不同字符的边界位置,因为切片要求的索引必须落在字符之间,也就是 utf-8 的边界,例如中文在 utf-8 中占用 3 个字节,下面的代码就不对:
Rustlet s = "你好世界"; let a = &s[0..2];因为我们直接去了前两个字节,但是一个中文占三个字节,如果是
&s[0..3],那么程序就不会崩溃,解决这个问题可以查看 utf-8 切片
另外,由于切片是对几何的部分引用,因此不仅仅字符串有切片,其他集合类型也有,例如数组:
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3]; // [2, 3]
操作字符串
String 类型是可变字符串,使用 String::from 定义
追加(push)
使用实例的 push_str 或者 push,前者可以追加字符串字面量,后者追加字符 char,两者都会修改原来的字符串,并不会返回新字符串,另外需要注意字符串变量必须使用 mut 关键字修饰。
fn main() {
let mut s = String::from("Hello ");
s.push_str("rust");
println!("{}", s); // Hello rust
s.push('!');
println!("{}", s); // Hello rust!
}
插入(insert)
使用实例的 insert_str() 或者 insert() 方法插入字符串字面量,前者插入字符串,后者插入字符。两者都会修改原来的字符串,并不会返回新字符串
fn main() {
let mut s = String::from("Hello rust");
s.insert(5, ',');
println!("{}", s); // Hello, rust
}
同样插入的索引是根据字符占的字节来说的,如果索引不在
utf-8边界也会报错,例如以下报错代码代码:Rustfn main() { let mut s = String::from("你好 世界"); // 中文字符在 utf-8 中占 3 字节,索引 2 不是边界 s.insert(2, ','); println!("{}", s); // Hello, rust }
替换(Replace)
replace
是用于 String 和 &str 类型,该类型不会修改原来的字符串,而是返回一个新的字符串
let s = String::from("hello rust, hello rust");
let new_str = s.replace("rust", "world");
println!("{}", new_str); // hello world, hello world
replacen
与 replace 一样,只不过接受第三个参数,限制替换的个数:
let s = String::from("hello rust, hello rust");
let new_str = s.replacen("rust", "world", 1);
println!("{}", new_str); // hello world, hello rust
replace_range
该方法会修改原来的字符串,因此只适用于 String 类型,接受两个参数,第一个参数表示范围,第二个表示需要替换的字符串
let mut s = String::from("hello rust,");
s.replace_range(6.., "world");
println!("{}", s); // hello world
删除(Delete)
与字符串删除相关的方法有 4 个:pop, remove, truncate 和 clear,四个方法均会修改原来的字符串,因此仅适用于 String 类型
pop删除并返回字符串的最后一个字符
删除字符串的最后一个字符,如果存在返回值,其返回值是一个 Option 类型,如果字符串为空,则返回 None
let mut s = String::from("he");
let ch: Option<char> = s.pop();
match ch {
Some(str) => println!("{}", str),
None => println!("没有字符了")
}
remove删除指定位置的字符
返回删除位置的字符串,只接受一个参数,表示该字符起始索引位置,remove 和其他字符串操作一样,都是按字节处理,因为位置不合法会报错:
let mut s = String::from("你好 世界");
s.remove(0);
println!("{}", s); // 好 世界
truncate删除字符串中从起始到指定位置的全部字符
该方法无返回值,也是按照字节来处理字符串的,如果参数位置不是合法的字符边界,则会发生错误
let mut s = String::from("hello world");
s.truncate(5);
println!("{}", s); // hello
clear清空字符串
let mut s = String::from("hello world");
s.clear();
println!("{}", s);
链接(Concatenate)
- 使用
+或者+=
使用 + 或者 += 连接字符串,要求右边的参数必须为字符串的切片引用(Slice)类型,+ 是返回一个新字符串,所以变量声明可以不需要 mut 关键字修饰
let str_append = String::from("hello ");
let str_rust = String::from("rust");
let result = str_append + &str_rust;
let mut result = result + "!";
result += "!!!!";
println!("{}", result); // hello rust!!!!!
注:
String + &str会返回一个String,所以后续还可以进行+操作
- 使用
format!连接字符串
format! 适用于 String 和 &str,其用法与 print! 类似,该方法返回一个 String 类型
let prefix = "hello";
let suffix = "world";
let full = format!("{} {}", prefix, suffix);
println!("{}", full); // hello world
字符串转义
我们可以通过转义的方式 \ 输出 ASCII 和 Unicode 字符:
fn main() {
// 通过 \ + 字符的十六进制表示,转义输出一个字符
let byte_escape = "I'm writing \x52\x75\x73\x74!";
println!("What are you doing\x3F (\\x3F means ?) {}", byte_escape);
// \u 可以输出一个 unicode 字符
let unicode_codepoint = "\u{211D}";
let character_name = "\"DOUBLE-STRUCK CAPITAL R\"";
println!(
"Unicode character {} (U+211D) is called {}",
unicode_codepoint, character_name
);
// 换行了也会保持之前的字符串格式
// 使用\忽略换行符
let long_string = "String literals
can span multiple lines.
The linebreak and indentation here ->\
<- can be escaped too!";
println!("{}", long_string);
}
当然,在某些情况下,可能你会希望保持字符串的原样,不要转义:
fn main() {
println!("{}", "hello \\x52\\x75\\x73\\x74");
let raw_str = r"Escapes don't work here: \x3F \u{211D}";
println!("{}", raw_str);
// 如果字符串包含双引号,可以在开头和结尾加 #
let quotes = r#"And then I said: "There is no escape!""#;
println!("{}", quotes);
// 如果还是有歧义,可以继续增加,没有限制
let longer_delimiter = r###"A string with "# in it. And even "##!"###;
println!("{}", longer_delimiter);
}
操作 UTF-8 字符串
前文提到过 rust 不允许使用索引查找字符,而根据索引操作字符串也是以字节数为准
如果我们要以 Unicode 字符的方式遍历字符串,最好使用 chars 方法,例如:
for c in "你好世界".chars() {
println!("{}", c);
}
// 你
// 好
// 世
// 界
以字节形式:
for c in "你好世界".bytes() {
println!("{}", c);
}
输出:
228
189
160
229
165
189
228
184
150
231
149
140
获取子串
想要准确的从 UTF-8 字符串中获取子串是较为复杂的事情,例如想要从 hello你好नमस्ते 这种变长的字符串中取出某一个子串,使用标准库你是做不到的。 你需要在 crates.io 上搜索 utf8 来寻找想要的功能。
可以考虑尝试下这个库:utf8_slice。
结构体
结构体 struct 是一个比较高级的数据结构,在其他语言中,他可能叫做 object、record 等
语法
例如下面代码:
struct User {
username: String,
email: String
};
结构体使用 struct,后面紧跟结构体名称
该结构体名称是 User,拥有 2 个字段:username 和 email,均为可变 String 类型
创建实例
let mut user = User {
username: String::from("Plumbiu"),
email: String::from("plumbiuzz@gmail.com"),
active: bool,
};
注意点:
- 初始化实例时,每个字段都需要进行初始化
- 初始化时的字段顺序不需要和结构体定义时的一致
访问结构体字段
通过 . 操作符可以获取结构体实例内部的字段值,也可以修改它们:
let mut user = User {
username: String::from("Plumbiu"),
email: String::from("plumbiuzz@gmail.com"),
active: true,
};
user.email = String::from("xxx@gamil.com");
如果要修改结构体实例的属性时,结构体一定是
let mut可变的
简化结构体创建
我们可以创建一个构造函数,返回一个 User 实例:
fn build_user(email: String, username: String) -> User {
email: email,
username: username,
}
和 js 一样,上面的代码还可以简化,当结构体和参数同名时,可以直接简写:
fn build_user(email: String, username: String) -> User {
email,
username,
active: true,
}
结构体更新语法
如果我们想以已有的 user1 实例去构建 user2,也可以使用类似 js 的展开运算符,只不过 rust 中少了一个点:..
let user2 = {
email: String::from("xxx@qq.com"),
..user1
}
..必须在结构体尾部使用
上述代码中,我们将
user1的参数赋值给了 user2 参数,会自动触发 rust 的所有权转移,但是只有username发生了所有权转移,因为active字段是具有Copy属性的但这并不意味着
user1无法被使用,只是发生所有权转移的字段无法使用,例如user.active仍然可以访问
结构体内存排列
先来看以下代码:
#[derive(Debug)]
struct File {
name: String,
data: Vec<u8>,
}
fn main() {
let f1 = File {
name: String::from("f1.txt"),
data: Vec::new(),
};
let f1_name = &f1.name;
let f1_length = &f1.data.len();
println!("{:?}", f1);
println!("{} is {} bytes long", f1_name, f1_length);
}
上面定义的 File 结构体在内存中的排列如下图所示: 
从图中可以清晰地看出 File 结构体两个字段 name 和 data 分别拥有底层两个 [u8] 数组的所有权(String 类型的底层也是 [u8] 数组),通过 ptr 指针指向底层数组的内存地址,这里你可以把 ptr 指针理解为 Rust 中的引用类型。
该图片也侧面印证了:把结构体中具有所有权的字段转移出去后,将无法再访问该字段,但是可以正常访问其它的字段。
元组结构体(Tuple Struct)
结构体必须要有名称,但是结构体字段可以没有名称,这种结构体成为元组结构体,例如:
struct Color(i32, i32, i32);
let black = Color(0, 0, 0);
单元结构体(Unit-like Struct)
如果我们定义一个类型,但是不关心该类型的内容,只关心行为时,可以使用单元结构体:
struct AlwaysEqual;
let subject = AlwaysEqual;
// 我们不关心 AlwaysEqual 的字段数据,只关心它的行为,因此将它声明为单元结构体,然后再为它实现某个特征
impl SomeTrait for AlwaysEqual {
}
打印结构体信息
上面代码中,我们使用了 #[derive(Debug)] 对结构体进行了标记,这样才能使用 println!("{:?}", s) 的方式进行打印,如果不加就会报错
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
// 使用 {} 格式化输出
println!("rect1 is {}", rect1);
}
报错信息:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
= help: the trait `std::fmt::Display` is not implemented for `Rectangle`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
错误信息告诉我们,我们的结构体没有实现 Display 特征,如果我们想要使用 {} 来格式化输出,那对应的类型就必须实现 Display 特征
如果按上面的 note 所说,将 {} 换成 {:?},运行后的报错信息:
error[E0277]: `Rectangle` doesn't implement `Debug`
= help: the trait `Debug` is not implemented for `Rectangle`
= note: add `#[derive(Debug)]` to `Rectangle` or manually `impl Debug for Rectangle`
此时编译器让我们实现 Debug 特征,并额外提示我们可以加 #[derive(Debug)]
Rust 默认不会为我们实现 Debug,为了实现,有两种方式可以选择:
- 手动实现
- 使用
derive派生实现
后者的实现更为简单,因此正确的写法应该是:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {:?}", rect1);
}
上面的打印结果:
rect1 is Rectangle { width: 30, height: 50 }
如果我们想要格式化更好的输出结果,可以使用 {:#?} 代替 {:?}:
rect1 is Rectangle {
width: 30,
height: 50,
}
枚举
枚举(enumeration)允许我们通过列举可能的成员定义一个枚举类型,例如扑克牌花色:
enum PokerSuit {
Clubs,
Spades,
Diamonds,
Hearts,
}
一张扑克牌只能有四种花色,这种特性就非常适合枚举,因为枚举值只能是其中某一个成员。枚举是一个类型,它会包含所有可能的枚举成员,而枚举值是该类型中的具体某个成员的实例。
枚举值
创建 PokerSuit 枚举类型的两个成员实例:
let heart = PokerSuit::Hearts;
let diamond = PokerSuit::Diamonds;
我们通过 :: 操作符来访问 PokerSuit 下的具体成员,根据代码类型提示,heart 和 diamond 都是 PokerSuit 枚举类型的,我们可以定义一个函数使用它们:
#[derive(Debug)]
enum PokerSuit {
Clubs,
Spades,
Diamonds,
Hearts,
}
fn main() {
let heart = PokerSuit::Hearts;
let diamond = PokerSuit::Diamonds;
print_suit(heart);
print_suit(diamond);
}
fn print_suit(card: PokerSuit) {
println!("{:?}",card);
}
print_suit 函数的参数类型是 PokerSuit,因此我们可以把 heart 和 diamond 传给它,虽然它俩是 PokerSuit 的成员实例,但是它们被 rust 定义为 PokerSuit 类型
扑克牌还会带有值,那么枚举如何实现呢?我们可以将数据关联到枚举中,类似元组结构体的写法:
enum PokerCard {
Clubs(u8),
Spades(u8),
Diamonds(u8),
Hearts(u8),
}
fn main() {
let c1 = PokerCard::Spades(5);
let c2 = PokerCard::Diamonds(13);
}
数组
rust 中数组有两种,一种是速度很快但是长度固定的 array,另一种是可动态增长的但有性能孙好的 Vector,array 为数组,Vector 为动态数组
对于数组 array 有以下要素:
- 长度固定
- 元素必须为相同类型
- 线性排序
数组在 Rust 中是基本类型,长度固定,与其他语言不同
创建数组
rust 中的数组定义与 javascript 类似:
let arr = [1, 2, 3, 4, 5];
这种方式定义的数组,大小固定、长度固定,因此数组(array)是存储在栈上
访问数组元素
跟大多数语言一样,我们可以通过索引获取数组元素:
let a = [1, 2, 3, 4, 5 , 6];
let first = a[0]; // 获取 a 数组第一个元素
let second = a[1]; // 获取第二个元素
另外,rust 还可以使用 [类型;长度] 语法初始化一个某个值重复出现 N 次的数组:
let a = [3;5]
与下面代码效果相同:
let a = [3, 3, 3, 3, 3];
越界访问:
rust 检查器不会检查数组越界,但是如果编译运行会出现 panic,例如以下代码:
a[100];
报错信息:
println!("{}", a[100]);
| ^^^^^^ index out of bounds: the length is 6 but the index is 100
|
= note: `#[deny(unconditional_panic)]` on by default
error: aborting due to previous error
数组元素为非基础类型:
实际开发中,数组元素会存在非基本类型,例如:
let arr = [String::from("hello"); 3];
println!("{:#?}", arr);
那么会编译错误,因为基本类型在 rust 赋值是以 Copy 的形式,而复杂类型都没有深拷贝,这能一个一个创建,所以无法复制 3 次
如果我们将上面代码中写成:
let arr = [String::from("hello"), String::from("hello"), String::from("hello")];
println!("{:#?}", arr);
虽然可以编译通过,但很难看
正确的方法应该调用 std::array::from_fn:
let arr: [String; 3] = std::array::from_fn(|_i| String::from("hello"));
println!("{:#?}", arr);
数组切片
数组切片允许我们使用数组的一部分:
let a: [i32; 5] = [1, 2, 3, 4, 5];
let slice: &[i32] = &a[1..3];
assert_eq!(slice, &[2, 3]);
**上面的数组切片 slice 的类型是 &[i32]**,与之对比,数组的类型是 [i32;5],简单总结下切片的特点:
- 切片的长度可以与数组不同,并不是固定的,而是取决于你使用时指定的起始和结束位置
- 创建切片的代价非常小,因为切片只是针对底层数组的一个引用
- 切片类型[T]拥有不固定的大小,而切片引用类型&[T]则具有固定的大小,因为 Rust 很多时候都需要固定大小数据类型,因此&[T]更有用,
&str字符串切片也同理
流程控制
if else
几乎所有的编程语言都有 if else,rust 与其他大部分语言的不同是,它可以省略后面的括号,和 go 一样:
if condition == true {
// ...
} else {
// ...
}
配合表达式,if 语句可以返回值
fn main() {
let condition = true;
let number = if condition {
5
} else {
6
};
println!("{}", number);
}
for 循环
for 循环是最常用的循环:
for i in 1..=5 {
println!("{}", i);
}
我们可以使用 .. 或者 ..= 语法创建连续序列
使用
for循环往往使用集合的引用形式,因为所有权会转移到 for 语句块中,后面就用不了这个集合了Rustfor item in &container { // ... }
如果要在循环中,修改元素,必须使用 mut 关键字:
for item in &mut collection {
// ...
}
总结如下:
| 使用方法 | 等价使用方式 | 所有权 |
|---|---|---|
for item in collection | for item in IntoIterator::into_iter(collection) | 转移所有权 |
for item in &collection | for item in collection.iter() | 不可变借用 |
for item in &mut collection | for item in collection.iter_mut() | 可变借用 |
循环中获取元素索引:
let a = [4, 3, 2, 1];
for (i, v) in a.iter().enumerate() {
println("第{}个元素是{}", i + 1, v);
}
如果只想循环某个流程 10 次,又不想声明一个变量来控制:
for _ in 0..10 {
// ...
}
while 循环
和其他语言一样,这里不多介绍
loop 循环
loop 循环是一种无限循环,只能在内部通过 break 关键字停止:
let n = 1;
loop {
if (n > 5) {
break;
}
n++
}
模式匹配
rust 中,模式匹配最常用的是 match 和 if let
match 匹配
match 匹配的通用模式:
match target {
模式1 => 表达式1,
模式2 = > {
语句1;
语句2;
表达式2
},
_ => 表达式3 // 默认,相当于 switch 中的 default
}
在我们之前删除字符串的例子中,返回的类型是一个 Option 类型,表示可能为空,我们可以使用 match 关键字判断是否为空:
let mut str = String::from("hello world");
let pop_str = str.pop();
match pop_str {
Some(ch) => { println!("{}", ch); },
None => { println!("数值为空"); }
}
match匹配中可以指名更确起的Some值,例如:Rustmatch pop_str { Some('d') => println!("第一个分支:{}", ch), Some(ch) => println!("第二个分支{}", ch), _ => println!("默认分支"), }
使用 match 表达式赋值:
match 本身就是一个表达式,因此可以赋值:
enum Ipddr {
Ipv4,
Ipv6,
}
fn main() {
let address = Ipddr::Ipv6;
let ip_str = match address {
Ipddr::Ipv4 => "127.0.0.1",
_ => "::1",
};
println!("{}", ip_str); // ::1
}
因为这里匹配到 _ 分支,所以将 "::1" 赋值给了 ip_str
穷尽匹配
如果 match 没有匹配到所有情况,会报错:
enum Direction {
East,
West,
North,
South
}
fn main() {
let dire = Direction::East;
match dire {
Direction::East => println!("East!"),
Direction::West => println!("West!"),
Direction::North => println!("North!"),
}
}
上述代码中,我们没有使用匹配 South,所以会报错
单分支多模式
上面代码都是单分支单模式匹配,rust 提供了 | 语法,允许我们单个分之中匹配多个值:
let x = 1;
match x {
1 | 2 => println!("one or two"),
3 => println!("three"),
_ => println!("anything"),
}
序列 ..= 指定匹配范围
let x = 5;
match x {
1..=5 => println!("one through five"),
_ => println!("something else"),
}
上面是针对数字的,事实上,rust 也可以匹配字符,例如:
let x = 'c';
match x {
'a'..='j' => println!("a - j"),
'k'..='z' => println!("j - z"),
_ => println!("啥都没匹配到")
}
匹配额外条件
匹配守卫(match guard) 是一个位于 match 分支模式之后额外的 if 条件:
let num = Some(4);
match num {
Some(x) if x < 5 => println!("less than five: {}", x),
Some(x) => println!("{}", x),
None => (),
}
if let 匹配
有时候我们只需要匹配一个值,其他值忽略的场景,如果使用 match,就要写成下面这样
let v = Some(3);
match v {
Some(3) => println!("three"),
_ => ()
}
我们只想匹配 v 为 u8 的情况,但却写了 _ => () 一串多余的代码,为了简化这个操作,我们可以使用 if let 匹配
let num = Some(3);
if let Some(num) = num {
println!("hello, {:?}", num);
}
以上代码只是展示使用,实际使用编译器会提前报错提示,
num类型永远是正确匹配的
当然,存在 if let 匹配,也就存在着 while let 条件循环匹配:
let mut stack = Vec::new();
stack.push(1);
stack.push(2);
stack.push(3);
while let Some(top) = stack.pop() {
println!("{}", top);
}
这里注意,rust 期望
Some(top)值类型在前,判断的元素在后,上述代码如果写成while let stack.pop() = Some(top)语法报错
matches! 宏
matches! 将一个表达式根模式进行匹配,然后返回匹配的结果 true 或者 false
例如,我们想过滤一个动态数组,只保留其内部某个值:
enum MyEnum {
Foo,
Bar
}
fn main() {
let v = vec![MyEnum::Foo,MyEnum::Bar,MyEnum::Foo];
}
现在我们要只保留 v 数组中的 MyEnum::Foo 值,其他语言可能会这么写:
v.iter().filter(|x| x === MyEnum::Foo)
但实际上,上述代码会报错,报错信息:
binary operation `==` cannot be applied to type `&&MyEnum`
v 数组元素的类型是 &&MyEnum,无法进行比较,我们可以使用 match 匹配改写,当然还有一种更加简洁的方式,使用 matches:
v.iter().filter(|x| matches!(x, MyEnum::Foo))
变量遮蔽
match 和 if let 都是一个新的代码块,这里的绑定相当于新变量,如果使用同名变量,就会发生变量遮蔽,例如:
fn main() {
let age = Some(30);
println!("在匹配前,age是{:?}",age);
if let Some(age) = age {
println!("匹配出来的age是{}",age);
}
println!("在匹配后,age是{:?}",age);
}
运行结果:
在匹配前,age是Some(30)
匹配出来的age是30
在匹配后,age是Some(30)
可以看到在 if let 语法块中,age 的类型是 i32,遮蔽了匹配之前的类型,这种现象对于 match 也同理,因此最好不要同名:
fn main() {
let age = Some(30);
println!("在匹配前,age是{:?}",age);
if let Some(x) = age {
println!("匹配出来的age是{}",x);
}
println!("在匹配后,age是{:?}",age);
}
Option 解构
Option 是一个枚举类型,用来解决 Rust 中变量是否有值的问题,定义如下:
enum Option<T> {
some(T),
None,
}
也就是说一个变量要么有值:Some<T>,要么为空:None,我们可以通过 match 来匹配
Option、Some、None为了方便,都包含在了prelude中,可以直接通过名称使用,而无需Option::Some去调用,但是千万不要忘记Some和None是Option下的成员
匹配 Option<T>
我们举一个例子就能明白:
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(n) => Some(n + 1),
None => None
}
}
fn main() {
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}
解构匹配
我们熟悉的解构,其实也是一种匹配,例如:
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x: a, y: b } = p;
assert_eq!(0, a);
assert_eq!(7, b);
}
Rust 中对结构体的解构匹配,需要在
let关键字后面加上类型,否则报错
对元组结构体同理:
struct Point(i32, i32);
fn main() {
let p = Point(4, 5);
let Point (x, y) = p;
println!("x: {}", x); // 4
println!("y: {}", y); // 5
}
如果不是结构体元组,而是普通的元组,那么不需要在 let 关键字后面加上类型:
let p = (4, 5);
let (x, y) = p;
println!("x: {}", x); // 4
println!("y: {}", y); // 5
同理对数组也是:
let arr: [u16; 2] = [114, 514];
let [x, y] = arr;
使用 .. 忽略:
let arr: [i32; 4] = [1, 2, 3, 4];
let [x, .., y] = arr;
println!("x: {}", x); // 1
println!("y: {}", y); // 4
使用 _ 忽略
let arr: [i32; 4] = [1, 2, 3, 4];
let [x, _, y, _] = arr;
println!("x: {}", x); // 1
println!("y: {}", y); // 3
_不仅可以忽略解构时的值,也可以使用在函数参数中,表示我们没有使用这个值,同时一些函数的返回值我们不想处理,也可以使用_变量名称来省略
@ 绑定
@ 运算符允许为一个字段绑定另一个变量,例如下面案例我们希望测试 Message::Hello 的 id 字段是否位于 3..=7 范围内,同时使用 id 字段:
let msg = Message::Hello { id: 5 };
match msg {
Message::Hello { id: id_val @ 1..=5 } => {
println!("id 值为 {}", id_val);
},
Message::Hello { id: 6..=10 } => {
// 这个分支下无法使用 id
println!("id 在第二个分支上");
},
Message::Hello { id } => {
println!("id 值为 {}", id);
}
}
@运算符在绑定新变量的后面
@前绑定后解构(Rust 1.56新增)
使用 @ 绑定新变量的同时,对目标进行解构:
#[derive(Debug)]
struct Point {
x: i32,
y: i32,
}
fn main() {
let p @ Point { x: px, y: py } = Point { x: 10, y: 23 };
println!("x: {}, y: {}", px, py);
println!("{:?}", p);
let point = Point { x: 10, y: 5 };
if let p @ Point { x: 10, y } = point {
println!("x is 10, y is {} in {:?}", y, p);
} else {
println!("x i not 10");
}
}
在之前解构时,
let后面要跟着类型,而如果使用@运算符绑定新变量,需要在前面使用
新特性(Rust 1.53新增)
match 1 {
num @ (1 | 2) => {
println!("num is 1 or 2, {}", num);
}
_ => {}
}
(1 | 2)是一个整体,一定要用括号包住,不然报错
方法
rust 中的方法类似于 class 中的方法,不同的是,rust 往往和对象成对出现,以下是 rust 和其他编程语言的区别:

rust 的对象定义和方法定义式分离的,这种方法会大大提高使用者的灵活度
定义方法
rust 使用 impl 实现方法,例如:
struct Circle {
x: f64,
y: f64,
radius: f64,
}
impl Circle {
// new 是 Circle 的关联函数,因为它的第一个参数不是 self,且 new 并不是关键字
// new 通常用于初始化当前结构体的实例
fn new(x: f64, y: f64, radius: f64) -> Circle {
Circle { x, y, radius }
}
// Circle 的方法,&self 表示借用当前的 Circle 的结构体
fn area(&self) -> f64 {
std::f64::consts::PI * (self.radius * self.radius)
}
}
fn main() {
let c = Circle::new(1.0, 2.0, 3.5);
println!("面积为:{}", c.area());
}
self、&self 和 &mut self
self 非常重要,在上述代码中,我们使用 &self 替代 circle: &Circle,&self 其实是 self: &Self 的简写,在一个 impl 块内,Self 类型指代被实现方法的结构体类型,self 是此类型实例,总之,self 指代的是 Circle 结构体实例
self 也依然有所有权的概念:
self表示Circle的所有权转移到该方法中,较为少见&self表示该方法对Rectangle的不可变借用&mut self表示可变借用
方法名和属性名相同
rust 中允许方法名和属性名相同:
struct Circle {
x: f64,
y: f64,
radius: f64,
}
impl Circle {
fn new(x: f64, y: f64, radius: f64) -> Circle {
Circle { x, y, radius }
}
fn area(&self) -> f64 {
std::f64::consts::PI * (self.radius * self.radius)
}
// radius 方法与 radius 属性同名
fn radius(&self) -> f64 {
f64::sqrt(self.area() / std::f64::consts::PI)
}
}
fn main() {
let c = Circle::new(1.0, 2.0, 3.5);
println!("面积为:{}", c.area());
println!("半径为:{}", c.radius());
}
带有多个参数的方法
方法和函数一样,可以使用多个参数,只是除了 new 方法以外,其他函数调用时传入的参数从第二个开始计算(第一个是 self)
impl Circle {
compare(&self, c: &Circle) -> bool {
&self.radius > c.radius
}
}
fn main() {
let c1 = Circle::new(1.0, 2.0, 5.0);
let c2 = Circle::new(4.0, 1.0, 6.0);
println!("{}", c1.compare(&c2));
}
关联函数
rust 中规定没有 self 的函数被称之为关联函数,因为没有 self,不能用 f.xxx() 形式调用,因为他是一个函数而不是方法
Rust 有一个约定俗成的规则,用
new作为构造器的名称,处于设计上考虑,rust 特地没有用new作为关键字
因为是函数,所以不能 . 的方式,而是用 :: 来调用。这个方法位于结构体的命名空间中::: 语法用于关联函数和模块创建的命名空间
多个 impl 定义
rust 允许我们为一个结构体定义多个 impl 块,目的是提高更多的灵活性和代码组织性:
impl Circle {
fn new(x: f64, y: f64, radius: f64) -> Circle {
Circle { x, y, radius }
}
fn area(&self) -> f64 {
std::f64::consts::PI * (self.radius * self.radius)
}
}
impl Circle {
fn radius(&self) -> f64 {
f64::sqrt(self.area() / std::f64::consts::PI)
}
}
为枚举实现方法
rust 的枚举类型之所以强大,是因为它还可以实现方法:
#![allow(unused)]
#[derive(Debug)]
enum Message {
User(String),
Target,
}
impl Message {
fn call(&self) {
println!("打给了, {:?}", self::Message::Target)
}
}
fn main() {
let m = Message::User("gxj".to_string());
m.call();
}
泛型(Generics)
假设我们有一个计算两个数之和的函数,我们需要考虑 i8、u8、f32、f64 ... 各种类型,类似下面代码:
fn add_i8(a:i8, b:i8) -> i8 {
a + b
}
fn add_i32(a:i32, b:i32) -> i32 {
a + b
}
fn add_f64(a:f64, b:f64) -> f64 {
a + b
}
而使用泛型后,我们只需要写一个函数即可:
fn add<T: std::ops::Add<Output = T>>(a: T, b: T) -> T {
a + b
}
不是所有类型都可以相加,所以我们使用
std::ops::Add<Output = T>限制范围,这个性质叫做 特征(Trait)
详解
上面的 T(type 缩写) 是泛型参数,这个名字可以随便起,除非有特殊性含义,一般越少越好
使用泛型参数,有一个先决条件,必需在使用前对其进行声明:
fn largest<T>(list: &[T]) -> T
该函数作用是从列表中找出最大值,其中列表中的元素类型为 T
&[T]是数组切片类型
一个常见的错误实现:
fn largest<T>(list: &[T]) -> T {
let mut largest = list[0];
for &item in list.iter() {
if item > largest {
largest = item;
}
}
largest
}
乍一看没什么问题,但是有一个很严重的问题:不是所有的类型都可以比较,因此我们需要添加 std::cmp::PartialOrd 特征,另外,我们需要注意的是,如果不添加 &,会导致所有权的转移
fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list.iter() {
if item > largest {
largest = &item;
}
}
largest
}
结构体中使用泛型
struct Point<T> {
x: T,
y: T,
}
上面约束了 x 和 y 必须是相同类型,如果不是相同类型,会发生报错,例如:
let p = Point { x: 1, y: 1.1 }
如果要希望 x 和 y 是不同类型,可以添加类型:
struct Point<T, U> {
x: T,
y: U,
}
枚举使用泛型
以 Option 为例,rust 中的 Option 源码:
enum Option<T> {
Some(T),
None
}
另外对于另外一个 rust 比较常见的类型 Result:
enum Result<T, E> {
Ok(T),
Err(E),
}
方法中使用泛型
既然函数中可以使用泛型,那么与函数类似的方法也可以:
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> T {
&self.x
}
}
使用泛型参数前,依然需要提前声明:impl<T>,只有提前声明,才可以在 Point<T> 中使用,这样 rust 就知道 Point 尖括号中的类型是泛型,而不是具体类型
如果是具体类型,可以直接在
Point的尖括号中指定,而不需要提前声明Rustimpl Point<i32> { fn distance_from_origin(&self) -> f32 { (self.x.powi(2) + self.y.powi(2)).sqrt() } }这段代码的意义是,只有
T为f32类型的Point<T>具有distance_from_origin方法,而且他的没有定义该方法
const 泛型
rust 数组中,[i32; 2] 和 [i32; 3] 是不同的数组类型,例如以下代码会报错:
// 方法只接受类型为 [i32; 3] 的代码
fn display_arr(arr: [i32; 3]) {
println!("{:?}", arr);
}
fn main() {
let arr1 = [1, 2, 3];
display_arr(arr1);
let arr2 = [1, 2];
display_arr(arr2);
}
我们可以修改一下代码,打印任意长度的 i32 类型:
fn display_arr(arr: &[i32]) {
println!("{:?}", arr);
}
fn main() {
let arr1 = [1, 2, 3];
display_arr(&arr1);
let arr2 = [1, 2];
display_arr(&arr2);
}
但是我们如果不仅想打印 i32 类型的数组,而是也可以打印例如字符串数组,这就要使用到泛型了:
fn display_arr<T: std::fmt::Debug>(arr: &[T]) {
println!("{:?}", arr);
}
fn main() {
let arr1 = [1, 2, 3];
display_arr(&arr1);
let arr2 = [1, 2];
display_arr(&arr2);
let arr3: [String; 3] = std::array::from_fn(|_x| String::from("Hello"));
display_arr(&arr3)
}
通过引用和泛型,很好解决了任意数组的打印,但是如果有些数组库,限制长度怎么办,我们可以使用 const 泛型,也就是针对值的泛型,可以很好的解决数组长度问题
fn display_arr<T: std::fmt::Debug, const N: usize>(arr: &[T; N]) {
println!("{:?}", arr);
}
当然,这段代码配合 where 才能发挥全部作用,即限制数组长度
特征(Trait)
特征 trait 在其他语言中可能叫做接口,之前的代码 #[derive(Debug)] 也是特征的使用,它在我们定义的类型(struct)上自动派生 Debug 特征。再比如:
fn add<T: std::ops::Add<Output = T>>(a: T. b: T) {
a + b
}
定义特征
如果不同类型具有相同的行为,那么我们就可以定义一个特征,然后为这些类型实现该特征。定义特征是把一些方法组合在一起,目的是定义一个实现某些目标所必须的行为的集合
例如,我们有 Post 和 Weibo 两种内容载体,而我们想对应的内容进行总结,无论是文章内容,还是微博内容,都可以进行总结,那么总结这个行为就是共享的,因此可以用特征来定义:
pub trait Summary {
fn summarize(&self) -> String;
}
几点:
- 使用
trait关键字声明特征,Summary是特征名 - 括号中定义了该特征的方法
特征只定义行为“看起来”是什么样的,而不定义行为具体是什么样的
为类型实现特征
以下例子为 Post 和 Weibo 实现了 Summary 特征:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct Post {
pub title: String,
pub author: String,
pub content: String,
}
impl Summary for Post {
fn summarize(&self) -> String {
format!("文章{}, 作者是{}", self.title, self.author)
}
}
pub struct Weibo {
pub usernmae: String,
pub content: String,
}
impl Summary for Weibo {
fn summarize(&self) -> String {
format!("{}发表了微博{}", self.usernmae, self.content)
}
}
实现特征的语法,例如 impl Summary for Weibo 翻译为中文就是 为 Weibo 实现 Summary 特征,后面花括号跟着实现该特征的具体方法
接着就可以在此类型上调用方法:
let post = Post { title: "Rust".to_string(), author: "gxj".to_string(), content: "hello rust".to_string() };
let weibo = Weibo { usernmae: "plumbiu".to_string(), content: "hello rust".to_string() };
println!("{}", post.summarize());
println!("{}", weibo.summarize());
特征定义与实现的位置(孤儿规则)
上面我们将 Summary 定义成了 pub 公开的。这样,如果他人想要使用我们的 Summary 特征,则可以引入到他们的包中,然后再进行实现。
关于特征实现与定义的位置,有一条非常重要的原则:如果你想要为类型 A 实现特征 T,那么 A 或者 T 至少有一个是在当前作用域中定义的! 例如我们可以为上面的 Post 类型实现标准库中的 Display 特征,这是因为 Post 类型定义在当前的作用域中。同时,我们也可以在当前包中为 String 类型实现 Summary 特征,因为 Summary 定义在当前作用域中。
但是你无法在当前作用域中,为 String 类型实现 Display 特征,因为它们俩都定义在标准库中,其定义所在的位置都不在当前作用域,跟你半毛钱关系都没有,看看就行了。
该规则被称为孤儿规则,可以确保其它人编写的代码不会破坏你的代码,也确保了你不会莫名其妙就破坏了风马牛不相及的代码
默认实现
我们可以在特征中定义具有默认实现的方法,这样其它类型无需再实现该方法,或者可以重载该方法:
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
这样子只需要这样写,也可以有一个默认方法实现,例如:
impl Summary for Post {}
impl Summary for Weibo {
fn summarize(&self) -> String {
format!("{}发表了微博{}", self.username, self.content)
}
}
可以看到,Post 选择默认实现,而 Weibo 重载了该方法,调用和输出如下:
println!("{}",post.summarize()); // (Read more...)
println!("{}",weibo.summarize()); // plumbiu发表了微博hello rust
默认实现运行调用特征自身的其他方法,哪怕这些方法没有默认实现:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
impl Summary for Post {
fn summarize_author(&self) -> String {
String::from("plumbiu")
}
}
println!("{}", post.summarize()); // (Read more from plumbiu...)
使用特征作为函数参数
特征不仅可以用来实现方法,还可以作为函数参数:
trait Summary {
fn summary(&self) -> String;
}
fn notify(item: &impl Summary) {
println!("Breaking news!{}", item.summary());
}
struct Weibo {}
impl Summary for Weibo {
fn summary(&self) -> String {
String::from("value")
}
}
fn main() {
let weibo = Weibo {};
notify(&weibo);
}
特征约束(trait bound)
impl Trait 这种语法其实是一个语法糖,完整的书写形式是:
fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}
简单情况下,impl Trait 就足够使用,但对于复杂场景,特征约束可以让我们拥有更大的灵活性,例如:
fn notify(item1: &impl Summary, item2: &impl Summary) {}
上面的代码倒是没有问题,但如果我们简化一点,或者要求两个参数必须为相同类型,那么特征约束实现起来更加方便:
fn notify<T: Summary>(item1: &T, item2: &T) {}
泛型类型
T说明了item1和item2必须拥有相同类型,同时T: summary说明了T必须实现Summary特征
多重约束
除了单个约束条件,我们还可以指定多个约束条件,例如让参数实现 Summary 特征外,还可以让参数实现 Diaplay 特征以控制格式化输出:
fn notify(item: &(impl Summary + Display)) {}
同理,还可以使用特征约束形式:
fn notify<T: Summary + Display>(item: &T) {}
Where 约束
当特征约束变得很多时,函数的签名将变得很复杂:
fn some_fn<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {}
上述代码可以使用 where 约束
fn some_fn<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
}
使用特征约束有条件地实现方法或特征
特征约束,可以让我们在指定类型 + 指定特征的条件下去实现方法,例如:
use std::fmt::Display;
struct Pari<T> {
x: T,
y: T,
}
impl<T> Pari<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pari<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest is x {}", self.x);
} else {
println!("The largest is y {}", self.y);
}
}
}
fn main() {
let p = Pari::new(4, 5);
p.cmp_display()
}
并不是所有的 Pair<T> 结构体对象都可以拥有,只有 T 同时实现了 Display + PartialOrd 的 Pari<T> 才可以拥有此方法
函数中返回 impl Trait
可以通过 impl Trait 来说明一个函数返回了一个类型,该类型实现了某个特征:
fn return_summarizable() -> impl Summary {
Weibo {
username: String::from("plumbiu"),
content: String::from("Hello Plumbiu")
}
}
这里要说明的是,Weibo 实现了 Summary 特征,完整代码;
trait Summary {
fn summary(&self) -> String;
}
struct Weibo {
username: String,
content: String,
}
impl Summary for Weibo {
fn summary(&self) -> String {
format!("作者: {}, 内容: {}", self.username, self.content)
}
}
fn return_summarizable() -> impl Summary {
Weibo {
username: "plumbiu".to_string(),
content: "Hello Plumbiu".to_string(),
}
}
fn main() {
let w = return_summarizable();
println!("{}", w.summary());
}
返回 impl Trait 的一个用处就是:如果我们的类型非常复杂,我们可以只返回一个 imple Trait
并且这种返回值方式有一个很大限制:只能有一个具体的类型,例如以下函数,虽然 Post 和 Weibo 都实现了 Summary 特征:
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
Post {
title: String::from(
"Penguins win the Stanley Cup Championship!",
),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
}
} else {
Weibo {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
}
}
}
以上代码会出错,因为返回了两个不同类型 Post 和 Weibo,如果要实现返回不同的类型,可以使用特征对象
修改之前的 largest 函数
新的函数要求 T 一定是可以比较(PartialOrd)并且可复制的(Copy)
fn largest<T: PartialOrd + Copy>(arr: &[T]) -> T {
// 由于可复制,不需要 & 符号
let mut max = arr[0];
// arr.iter() 返回引用
for &item in arr.iter() {
if item > max {
max = item
}
}
max
}
fn main() {
let num_list = vec![1, 2, 3, 4, 5];
println!("{}", largest(&num_list));
}
通过 derive 派生特性
在本书中,形如 #[derive(Debug)] 的代码已经出现了很多次,这种是一种特征派生语法,被 derive 标记的对象会自动实现对应的默认特征代码,继承相应的功能。
例如 Debug 特征,它有一套自动实现的默认代码,当你给一个结构体标记后,就可以使用 println!("{:?}", s) 的形式打印该结构体的对象。
再如 Copy 特征,它也有一套自动实现的默认代码,当标记到一个类型上时,可以让这个类型自动实现 Copy 特征,进而可以调用 copy 方法,进行自我复制。
总之,derive 派生出来的是 Rust 默认给我们提供的特征,在开发过程中极大的简化了自己手动实现相应特征的需求,当然,如果你有特殊的需求,还可以自己手动重载该实现。
详细的 derive 列表参见附录-派生特征。
调用方法需要引入特征
在一些场景中,使用 as 关键字做类型转换会有比较大的限制,因为想在类型转换上拥有完全的控制,例如处理错误,那么可以使用 TryInto:
fn main() {
let a: i32 = 10;
let b: u16 = 100;
let b_ = b.try_into().unwrap();
// 不写这段代码时,我们是不知道 b_ 的类型的
// 写上之后,rust 编译器自动将 b_ 转化为 i32 类型
if a < b_ {
println!("Ten is less than one hundred.");
}
}
其实上面代码引用了 std::convert::TryInto 特征,只是这个方法通过 std::prelude 提前引入到了当前作用域,所以不需要写 use std::convert::TryInto 也可以编译通过
特征对象
在之前的章节中,有一段代码无法通过编译:
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
Post {
// ...
}
} else {
Weibo {
// ...
}
}
}
由于 impl Trait 的返回值类型不支持多种不同类型,尽管 Post 和 Weibo 都实现了 Summary 特征
现在我们考虑一个问题,如果要做一款游戏,将多个对象渲染在屏幕上,这些对象属于不同类型,存储在列表中,渲染的时候,需要循环该列表并顺序渲染每个对象,在 Rust 中如何实现呢?
- 使用枚举
#[derive(Debug)]
enum UiObj {
Button,
SelectBox,
}
fn main() {
let objects = [UiObj::Button, UiObj::SelectBox];
for o in objects {
draw(o)
}
}
fn draw(o: UiObj) {
println!("{:?}", o);
}
这种方法虽然可行,但是却有很多问题,加入我们的对象不能事先明确地直到,或者别人也想要实现一个 UI 组件,实现这些,还需要手动增加一个成员
总之,编写这个 UI 库时,我们无法知道所有的 UI 对象类型,只知道:
- UI 对象的类型不同
- 需要一个统一的类型来处理这些对象,无论是作为函数参数还是作为列表中的一员
- 需要对每一个对象调用
draw方法
在拥有继承的语言中,可以定义一个名为 Component 的类,该类上有一个 draw 方法。其他的类比如 Button、Image 和 Table 都会从 Component 上继承 draw 方法,也可以覆盖 draw 方法定义自己的行为,这些类型都是 Component 实例,不过 rust 没有继承
特征对象定义
为了解决上面的问题,rust 引入了一个新概念 —— 特征对象
还是之前的 UI 库问题,我们先来为 UI 组件定义一个特征:
pub trait Draw {
fn draw(&self);
}
只要组件实现了 Draw 特征,就可以调用 draw 方法来进行渲染,假设有一个 Button 和 SelectBox 组件实现了 Draw 特征:
trait Draw {
fn draw(&self);
}
struct Button {
width: u32,
height: u32,
label: String,
}
impl Draw for Button {
fn draw(&self) {
// 绘制按钮代码
}
}
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>
}
impl Draw for SelectBox {
fn draw(&self) {
// 绘制 SelectBox 的代码
}
}
我们还需要一个动态数组来存储这些 UI 对象:
struct Screen {
components: Vec<?>
}
代码中的 ? 意思是:我们应该填入什么类型,
Box<T>智能指针,可以当成一个引用,不过它包裹的值会被强制分配到堆上,dyn是用来强调实现的特征是动态分配的,特征对象必须使用该关键字,Deref是一个特征,允许我们重载解引用运算符*
trait Draw {
fn draw(&self) -> String;
}
impl Draw for u8 {
fn draw(&self) -> String {
format!("f64: {}", *self)
}
}
impl Draw for f64 {
fn draw(&self) -> String {
format!("f64: {}", *self)
}
}
// 若 T 实现了 Draw 特征,则调用该函数时传入的 Box<T> 可以被隐式转换成函数签名中的 Box<dyn Draw>
fn draw1(x: Box<dyn Draw>) {
// 由于实现了 Deref 特征,Box 智能指针会自动解引用为它所包裹的值,然后调用该值对应的类型上定义的 draw 方法
x.draw();
}
fn draw2(x: &dyn Draw) {
x.draw();
}
fn main() {
let x = 1.1f64;
let y = 8u8;
draw1(Box::new(x));
draw1(Box::new(y));
draw2(&x);
draw2(&y);
}
上面代码几个非常重要的点:
draw1的函数参数是Box<dyn Draw>形式的特征对象,该特征对象是通过Box::new(x)方式创建的draw2函数参数是&dyn Draw形式的特征对象,该特征对象是通过&x方式创建的dyn关键字只用在特征对象的类型声明上,在创建时无需使用dyn
完善之前的 UI 组件代码,首先实现 Screen:
struct Screen {
components: Vec<Box<dyn Draw>>
}
Screen 中存储了一个动态数组,里面元素的类型是 Draw 特征对象:Box<dyn Draw>,任何实现了 Draw 特征的类型,都可以存放其中
再来为 Screen 定义 run 方法,用于将列表中的 UI 组件渲染在屏幕上:
impl Screen {
fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
至此,我们可以在列表中存储多种不同类型的实例,然后将它们使用同一个方法逐一渲染在屏幕上
再来看看通过泛型实现:
// trait 相当于接口,任何具有 Draw 特征的结构体等都必须实现 draw 方法
trait Draw {
fn draw(&self) -> String;
}
// Screen 结构体
struct Screen<T> {
components: Vec<T>,
}
// 只有 T 实现了 Draw 特征,才会具有 run 方法
impl<T> Screen<T>
where
T: Draw,
{
fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
// Button 结构体
struct Button {
width: u32,
height: u32,
}
// 为 Button 实现结构体
impl Draw for Button {
fn draw(&self) -> String {
println!("width: {}, height:{}", self.width, self.height);
"ok".to_string()
}
}
fn main() {
let s = Screen {
// component 必须全为 Button,增加其他类型就会报错
components: vec![Button {
width: 32,
height: 32,
}],
};
s.run();
}
上面的 Screen 的列表中,存储了类型为 T 的元素,然后在 Screen 中使用特征约束让 T 实现了 Draw,进而可以调用 draw 方法,但是这种写法限制了 Screen 实例的 Vec<T> 中每个元素必须全是 Button 或者 SelectBox 类型
如果只需要同质(相同类型)集合,更倾向于采用泛型+特征约束这种写法,这种写法更清晰,且性能更好(特征对象需要在运行时从
vtable动态查找需要调用的方法)
反正我们记住一点的是:特征 trait 相当于接口,结构体 struct 定义了类中的属性,而类中的方法使用 impl 关键字实现,同时 trait 实现也靠 impl
上面代码还是具有缺陷的,因为 Screen 中的 components 只能是同一个类型,修改后的代码:
// trait 相当于接口,任何具有 Draw 特征的实例都必须实现 draw 方法
trait Draw {
fn draw(&self) -> String;
}
struct Screen {
components: Vec<Box<dyn Draw>>,
}
impl Screen {
fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
struct Button {
width: u32,
height: u32,
}
impl Draw for Button {
fn draw(&self) -> String {
println!("width: {}, height:{}", self.width, self.height);
"ok".to_string()
}
}
struct SelectBox {
width: u32,
height: u32,
option: String,
}
impl Draw for SelectBox {
fn draw(&self) -> String {
println!(
"width: {}, height:{}, option: {}",
self.width, self.height, self.option
);
"ok".to_string()
}
}
fn main() {
let s = Screen {
components: vec![
Box::new(Button {
width: 32,
height: 32,
}),
Box::new(SelectBox {
width: 16,
height: 5,
option: String::from("hello"),
}),
],
};
s.run();
}
特征对象的动态分发
rust 中,泛型是在编译器完成处理的:编译器为每一个泛型参数对应的具体类型生成一份代码,这种方式是静态分发(static dispatch),因为是在编译期完成的,对于运行期性能完全没有任何影响
与静态分发对应的是动态分发(dynamic dispatch),这种情况下,直到运行,才能确定需要调用什么方法,之前的关键字 dyn 正是强调"动态"这一特点
当时用特征对象时,rust 必须使用动态分发,编译器无法知晓所有可能用于特征对象代码的类型,所以它也不知道应该调用哪个类型的哪个方法(例如 Button 和 SelectBox 的 draw 方法不同,但是编译器当我们使用不同类型的动态分发时,编译器无法处理不同类型的 draw 方法)
下面这张图很好的解释了静态分发 Box<T> 和动态分发 Box<dyn Trait> 的区别:
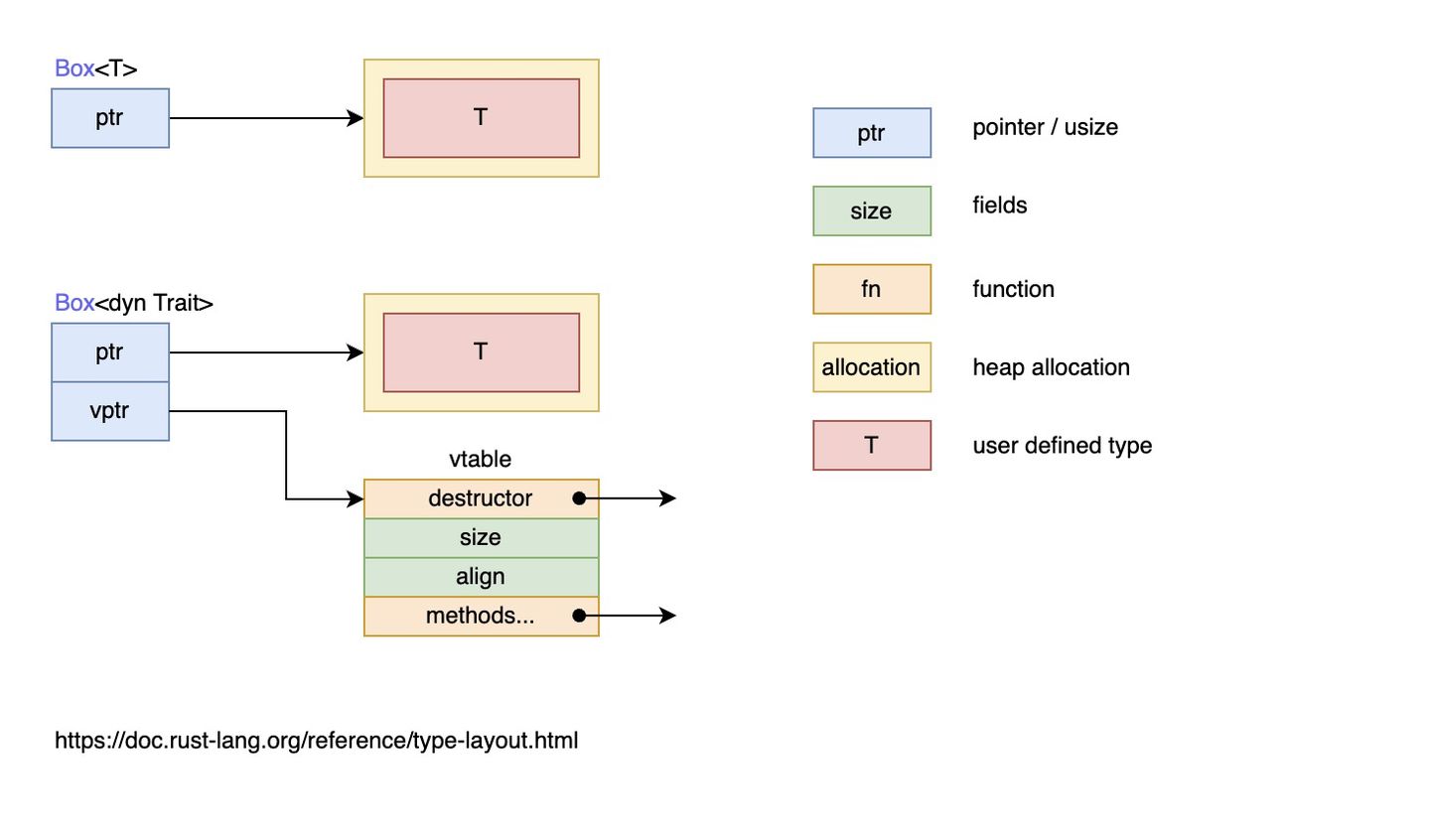
结合内容和上图可知:
- 特征对象大小不固定:对于某个特征,类型
A可以实现该特征,类型B也可以实现该特征,所以特征没有固定大小 - 几乎总是使用特征对象的引用方式:如
&dyn Draw或者Box<dyn Draw>- 虽然特征对象没有固定大小,但是它的引用类型的大小是固定的,由两个直振组成(
ptr和vptr),因此占用两个指针大小 - 一个指针
ptr指向了实现了特征Draw的具体类型的实例,也就是当作特征Draw来用的类型的实例,比如类型Button的实例,类型SelectBox的实例 - 另一个指针
vptr指向一个虚表vtable,vtable中保存了类型Button或类型SelectBox的实例对于可以调用的实现于特征Draw的方法。当调用方法时,直接从vtable中找到方法并调用。之所以要使用一个vtable来保存各实例的方法,是因为实现了特征Draw的类型有多种,这些类型拥有的方法各不相同,当将这些类型的实例都当作特征Draw来使用时(此时,它们全都看作是特征Draw类型的实例),有必要区分这些实例各自有哪些方法可调用
- 虽然特征对象没有固定大小,但是它的引用类型的大小是固定的,由两个直振组成(
简而言之,当类型 Button 实现了特征 Draw 时,类型 Button 的实例对象 btn 可以当做特征 Draw 的特征对象类型来使用,btn 中保存了作为特征对象的数据指针(指向类型 Button 的实例数据)和行为指针(指向 vtable)
注意:此时的
btn是Draw的特征对象的实例,而不再是具体类型Button的实例,而且btn的vtable只包含了实现自特征Draw的那些方法(比如draw),因此btn只能调用实现于特征Draw的draw方法,而不能调用类型Button本身实现的方法和类型Button实现于其他特征的方法。也就是说,btn是哪个特征对象的实例,它的vtable中就包含了该特征的方法。
Self 与 self
rust 中,有两个 self,一个指代当前的实例对象,一个指代特征或者方法类型的别名:
trait Draw {
fn draw(&self) -> Self;
}
#[derive(Clone)]
struct Button;
impl Draw for Button {
fn draw(&self) -> Self {
self.clone()
}
}
fn main() {
let button = Button;
let newb = button.draw();
}
上述代码中,self 指代的就是当前的实例对象,也就是 button.draw() 中的 button 实例,Self 则指代的是 Button 类型
特征对象的限制
不是所有特征都能拥有特征对象,只有对象安全的特征才行。当一个特征的所有方法都有如下形式时,它的对象才是安全的:
- 方法返回类型不能是
Self - 方法没有任何泛型参数
这很好理解,因为特征对象不需要知道实现改特性的具体类型是什么,如果特征方法返回了具体的 Self 类型,那么特征对象也不知道他是啥;而对于泛型类型参数,我们会放入具体的类型,而此类型变成了实现该特征类型的一部分
例如,标准库中的 Clone 特征就不符合对象安全的要求
pub trait Clone {
fn clone(&self) -> Self
}
总结
特征对象有很多用法
使用 dyn 返回特征
rust 编译器需要知道一个函数的返回类型占用多少内存。由于特征的不同实现,类型可能占用不同的内存,因此通过
impl Trait返回多个类型是不被允许的,我们可以返回一个dyn特征对象解决问题
例题:
trait Bird {
fn quack(&self) -> String;
}
struct Duck;
impl Duck {
fn swim(&self) {
println!("Look, the duck is swimming")
}
}
struct Swan;
impl Swan {
fn fly(&self) {
println!("Look, the duck.. oh sorry, the swan is flying")
}
}
impl Bird for Duck {
fn quack(&self) -> String {
"duck duck".to_string()
}
}
impl Bird for Swan {
fn quack(&self) -> String {
"swan swan".to_string()
}
}
fn main() {
// 填空
let duck = Duck {};
duck.swim();
let bird = hatch_a_bird(2);
// 变成鸟儿后,它忘记了如何游,因此以下代码会报错
// bird.swim();
// 但它依然可以叫唤
assert_eq!(bird.quack(), "duck duck");
let bird = hatch_a_bird(1);
// 这只鸟儿忘了如何飞翔,因此以下代码会报错
// bird.fly();
// 但它也可以叫唤
assert_eq!(bird.quack(), "swan swan");
println!("Success!")
}
// 实现以下函数
fn hatch_a_bird(idx: i32) -> Box<dyn Bird> {
match idx {
1 => Box::new(Swan {}),
_ => Box::new(Duck {}),
}
}
上述代码中,我们不知道 dyn Bird 结构体的大小,使用 Box 智能指针包裹
静态分发和动态分发
trait Foo {
fn method(&self) -> String;
}
impl Foo for u8 {
fn method(&self) -> String {
format!("u8: {}", *self)
}
}
impl Foo for String {
fn method(&self) -> String {
format!("string: {}", *self)
}
}
// 通过泛型实现以下函数
fn static_dispatch<T: Foo>(n: T) {
println!("{:?}", n.method());
}
// 通过特征对象实现以下函数
fn dynamic_dispatch(n: &dyn Foo) {
println!("{:?}", n.method());
}
fn main() {
let x = 5u8;
let y = "Hello".to_string();
static_dispatch(x);
dynamic_dispatch(&y);
println!("Success!")
}
对象安全
一个特征能变成特征对象,首先该特征必须是对象安全的,即该特征的所有方法都必须拥有以下特点:
- 返回类型不能是
Slef - 不能使用泛型参数
// 使用至少两种方法让代码工作
// 不要添加/删除任何代码行
trait MyTrait {
fn f(&self) -> Self;
}
impl MyTrait for u32 {
fn f(&self) -> Self { 42 }
}
impl MyTrait for String {
fn f(&self) -> Self { self.clone() }
}
fn my_function(x: Box<dyn MyTrait>) {
x.f()
}
fn main() {
my_function(Box::new(13_u32));
my_function(Box::new(String::from("abc")));
println!("Success!")
}
第一种,直接修改 my_function 参数:
// 使用至少两种方法让代码工作
// 不要添加/删除任何代码行
trait MyTrait {
fn f(&self) -> Self;
}
impl MyTrait for u32 {
fn f(&self) -> Self {
42
}
}
impl MyTrait for String {
fn f(&self) -> Self {
self.clone()
}
}
fn my_function(x: impl MyTrait) -> impl MyTrait {
x.f()
}
fn main() {
my_function(13_u32);
my_function(String::from("abc"));
println!("Success!")
}
第二种,干脆直接修改 Mytrait 特征:
// 使用至少两种方法让代码工作
// 不要添加/删除任何代码行
trait MyTrait {
fn f(&self) -> Box<dyn MyTrait>;
}
impl MyTrait for u32 {
fn f(&self) -> Box<dyn MyTrait> {
Box::new(42)
}
}
impl MyTrait for String {
fn f(&self) -> Box<dyn MyTrait> {
Box::new(self.clone())
}
}
fn my_function(x: Box<dyn MyTrait>) -> Box<dyn MyTrait> {
x.f()
}
fn main() {
my_function(Box::new(13_u32));
my_function(Box::new(String::from("abc")));
println!("Success!")
}
动态数组
动态数组类型用 Vec<T> 表示,允许我们存储多个值,这些值在内存中一个紧挨着另一个排列,因此访问其中某个元素成本非常低。动态数组只能存储相同类型的元素,如果要存储不同类型的元素,可以使用之前讲过的枚举类型或者特征对象
创建动态数组
在 rust 中,有多种方式可以创建动态数组
Vec::new
使用 Vec::new 创建动态数组是最符合 rust 编码规范额方式:
let v: Vec<i32> = Vec::new();
这里我们显式生命了类型 Vec<i32>,这是因为 rust 编译器无法从 Vec::new 中得到任何关于类型的信息,但是我们向后追加一个元素,rust 编译器就能推断出来了:
let mut v = Vec::new();
v.push(1);
如果预先知道存储的元素个数,可以使用
Vec::with_capacity(capacity)创建动态数组,提高性能
vec![]
使用宏 vec![] 创建动态数组,可以创建的同时给予初始化值:
let v = vec![1, 2, 3];
读取元素
rust 有两种方式可以读取动态数组的元素:
- 通过下标索引访问
- 使用
get方法
let v = vec![1, 2, 3, 4, 5, 6];
println!("第二个元素是 {}", &v[1]);
match v.get(2) {
Some(value) => println!("第三个元素是 {}", value),
None => println!("没有第三个元素"),
}
.get方法比索引查找更安全,因为.get返回的是一个Option类型,而通过下标索引会引起数组越界
同时借用多个数组
在之前的章节中,我们讲过如果修改不可变引用,会报错,动态数组中,很容易遇到这种问题:
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0]; // 不可变借用
v.push(6);
println!("The first element is: {first}");
first = &v[0]进行了不可变借用,而v.push进行了可变借用,如果v.push和first = &v[0]调换顺序,那么就可以成功编译了
迭代遍历 Vector
可以使用迭代的方式去遍历数组,这种方式比用下标的方式去遍历更安全也更高效:
let mut v = vec![1, 2, 3, 4, 5];
for item in &v {
// 这里的 item 是 &i32 类型,rust 会自动解引用
println!("{}", item); // 这里写成 *item 也可以
}
// 修改 Vector 中的元素
for item in &mut v {
// item 是 &mut i32,使用时必须解引用
*item *= 10;
}
println!("{:?}", v);
存储不同类型的元素
存储不同类型的元素可以使用枚举或者特征对象来实现
- 枚举实现
#[derive(Debug)]
enum IpAddr {
V4(String),
V6(String),
}
fn main() {
let v = vec![
IpAddr::V4("127.0.0.1".to_string()),
IpAddr::V6("::1".to_string())
];
for item in &v {
println!("{:?}", item);
}
}
虽然数组 v 中存储了两个不同的 ip 地址,但是它们都是 IpAddr 枚举类型的成员
- 特征对象实现
特征对象实现起来虽然比枚举麻烦,但是实际上,特征对象数组比枚举数组常用,主要在于特征对象非常灵活,而编译器对枚举限制较多,且无法动态增加类型
trait IpAddr {
fn display(&self) -> String;
}
struct V4;
impl IpAddr for V4 {
fn display(&self) -> String {
"127.0.0.1".to_string()
}
}
struct V6;
impl IpAddr for V6 {
fn display(&self) -> String {
"::1".to_string()
}
}
fn main() {
let v: Vec<Box<dyn IpAddr>> = vec![Box::new(V4), Box::new(V6)];
for item in &v {
println!("{}", item.display());
}
}
Vector 常用方法
初始化方法
let v_from = Vec::from([0, 0, 0]);
let v = vec![0; 3];
assert_eq!(v, v_from);
扩容
动态数组意味着如果我们增加元素,容量不足时,Vector 扩容(原来的 2 倍内存),所以,频繁扩容或者当元素数量较多需要扩容时,大量的内存拷贝会降低程序的性能
可以考虑初始化时指定一个实际的预估容量,尽量减少可能的内存拷贝:
let mut v = Vec::with_capacity(10);
v.extend([1, 2, 3]); // 附加数据到 v
println!("v 的长度是: {},容量是: {}", v.len(), v.capacity());
v.resize(100, 0); // 调整 v 的容量
println!("v 的长度是: {},容量是: {}", v.len(), v.capacity());
v.extend([1, 2, 3]); // 附加数据到 v
println!("v 的长度是: {},容量是: {}", v.len(), v.capacity());
v.shrink_to_fit(); // 释放剩余的容量,一般情况下,不会主动去释放容量
println!("v 的长度是: {},容量是: {}", v.len(), v.capacity());
打印结果:
v 的长度是: 3,容量是: 10
v 的长度是: 100,容量是: 100
v 的长度是: 103,容量是: 200
v 的长度是: 103,容量是: 103
其他方法
let mut v = vec![1, 2];
assert!(!v.is_empty()); // 检查 v 是否为空
v.insert(2, 3); // 在指定索引插入数据,索引值不能大于 v 的长度, v: [1, 2, 3]
assert_eq!(v.remove(1), 2); // 移除指定位置的元素并返回, v: [1, 3]
assert_eq!(v.pop(), Some(3)); // 删除并返回 v 尾部的元素,v: [1]
assert_eq!(v.pop(), Some(1)); // v: []
assert_eq!(v.pop(), None); // 记得 pop 方法返回的是 Option 枚举值
v.clear(); // 清空 v, v: []
let mut v1 = [11, 22].to_vec(); // append 操作会导致 v1 清空数据,增加可变声明
v.append(&mut v1); // 将 v1 中的所有元素附加到 v 中, v1: []
v.truncate(1); // 截断到指定长度,多余的元素被删除, v: [11]
v.retain(|x| *x > 10); // 保留满足条件的元素,即删除不满足条件的元素
let mut v = vec![11, 22, 33, 44, 55];
// 删除指定范围的元素,同时获取被删除元素的迭代器, v: [11, 55], m: [22, 33, 44]
let mut m: Vec<_> = v.drain(1..=3).collect();
let v2 = m.split_off(1); // 指定索引处切分成两个 vec, m: [22], v2: [33, 44]
Vector 的排序
rust 里,有两种排序算法,分别是稳定的 sort 和 sort_by,以及非稳定的 sort_unstable 和 sort_unstable_ny
稳定和非稳定区别在于:稳定排序对于相等的元素不会重新排序,而非稳定的则不会保证这一点
总体而言,非稳定的排序算法速度会优于稳定排序算法,同时,稳定排序还会额外分配原数组一般的空间
- 整数数组的排序
let mut v = vec![1, 5, 10, 2, 7, 6];
v.sort_unstable();
println!("{:?}", v); // [1, 2, 5, 6, 7, 10]
- 浮点数组的排序
浮点数组不能像整数数组一样,直接调用 sort 方法,因为浮点数当中,存在一个 NAN 值,这个数无法与其他浮点数对比,因此浮点数类型并没有实现全数值可比较 Ord 的特性,而是实现了部分可比较的特性 PartialOrd
了解这些,我们可以使用 partial_cmp 作为判断的依据:
let mut v = vec![1.0, 5.6, 10.3, 2.0, 15f32];
v.sort_unstable_by(|a, b| a.partial_cmp(b).unwrap());
println!("{:?}", v); // [1.0, 2.0, 5.6, 10.3, 15.0]
其中,
unwrap表示如果计算结果有错误,直接panic!
- 对结构体数组进行排序
#[derive(Debug)]
struct Person {
name: String,
age: u32,
}
impl Person {
fn new(name: String, age: u32) -> Person {
Person { name, age }
}
}
fn main() {
let mut v: Vec<Person> = vec![
Person::new("xj".to_string(), 12),
Person::new("pl".to_string(), 31),
Person::new("bl".to_string(), 22),
Person::new("xjj".to_string(), 16),
];
v.sort_by(|a , b| a.age.cmp(&b.age));
print!("{:?}", v);
}
输出结果:
[Person { name: "xj", age: 12 }, Person { name: "xjj", age: 16 }, Person { name: "bl", age: 22 }, Person { name: "pl", age: 31 }]
这样做似乎也没什么问题,但是 rust 的特征属性可以作用在结构体上,使得结构体也可以实现 Ord 特性(事实上,除了 Ord,还有 Eq、PartialEq、PartialOrd 这些特性)
#[derive(Debug, Ord, Eq, PartialEq, PartialOrd)]
struct Person {
name: String,
age: u32,
}
impl Person {
fn new(name: String, age: u32) -> Person {
Person { name, age }
}
}
fn main() {
let mut people = vec![
Person::new("Zoe".to_string(), 25),
Person::new("Al".to_string(), 60),
Person::new("Al".to_string(), 30),
Person::new("John".to_string(), 1),
Person::new("John".to_string(), 25),
];
people.sort_unstable();
println!("{:?}", people);
}
为结构体实现上述特征后,排序时是按照第一个具有以上特征的属性为准,例如上述为
age属性
HashMap
HashMap 和动态数组一样,也是 rust 标准库中提供的集合类型,HashMap 中存储的是一一映射的 KV 键值对,它的查询复杂度只有 O(1)
创建 HashMap
和动态数组一样,可以使用 new 方法来创建 HashMap,然后通过 insert 方法插入键值对
使用 new 方法
use std::collections::HashMap;
fn main() {
let mut posts = HashMap::new();
posts.insert("2021", "vue");
posts.insert("2022", "rust");
posts.insert("2023", "rust");
}
HashMap没有包含在prelude中跟
Vec一样,如果预先知道存储的KV对个数,可以使用HashMap::with_capacity(capacity)创建指定大小的HashMap避免频繁的内存分配和拷贝,提升性能
insert方法也兼顾**“查询、更新“**,但它返回的并不是插入的最新值,而是对应键值对的旧值,如果更新已有的数据,那么会覆盖
使用迭代器和 collect 方法创建
如果有张成绩单,那么一个合理的数据结构应该是 Vec<(String, u32)> 类型,这个数据跟表单十分契合,但是如果我们想根据一个人名查找它的成绩,那么动态数组就不适用了,我们需要将 Vec<String, u32> 映射为 HashMap<String, u32>
我们可以先 new 一个 HashMap,然后循环动态数组,将 kv 值 insert 进 HashMap 中,但这样不够简洁
rust 提供了一种方法:现将 Vec 转换为迭代器,在通过 collect 将迭代器元素收集后转为 HashMap:
use std::collections::HashMap;
fn main() {
let scores: Vec<(String, i32)> = vec![
("xj".to_string(), 100),
("xxj".to_string(), 90),
("xjj".to_string(), 80),
];
let scores_map: HashMap<String, i32> = scores.into_iter().collect();
println!("{:?}", scores_map);
}
所有权转移
HashMap 的所有权规则与其它 Rust 类型没有区别:
- 若类型实现
Copy特征,该类型会被复制进HashMap,因此无所谓所有权 - 若没实现
Copy特征,所有权将被转移给HashMap中
又是一个经常出错的例子:
use std::collections::HashMap;
fn main() {
let name = String::from("xj");
let age = 20;
let mut map = HashMap::new();
map.insert(name, age);
println!("name: {}", name);
println!("age: {}", age);
}
很简单,name 发生了所有权转移,转以后继续使用就会报错
处理方法是将 name 的引用作为键值,但一定确保生命周期和 HashMap 一致或更久
use std::collections::HashMap;
fn main() {
let name = String::from("xj");
let age = 20;
let mut map = HashMap::new();
map.insert(&name, age);
println!("name: {}", name);
println!("age: {}", age);
}
查询 HashMap
通过 get 方法可以获取元素:
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
scores.insert("Blue", 10);
scores.insert("Yellow", 10);
let score: Option<&i32> = scores.get("Blue");
}
上面注意的几项:
get方法返回的是Option<&i32>类型,当查询不到时,返回None,查询到时返回Some(&i32)&i32是对HashMap中值的借用,如果不使用借用,可能会发生所有权转移
但是如果我们只想获取 i32 类型的值该如何呢,使用以下代码:
let score: i32 = scores.get("Blue").copied().unwrap_or(0);
copied即返回copy后的数值之前的
unwrap在接受到None时,会引起panic,而这里的unwarp_or接受到None时,不会引起panic,而是返回参数里的默认值
可以通过循环遍历 kv 对:
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
scores.insert("Blue", 10);
scores.insert("Yellow", 10);
for (key, value) in &scores {
println!("{}: {}", key, value);
}
}
更新 HashMap 中的值
rust 提供了许多更新 HashMap 的方法:
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert("Blue", 10);
// 覆盖已有的值
let old = scores.insert("Blue",0 20);
assert_eq!(old, Some(10));
// 查询新插入的值
let new = scores.get("Blue");
assert_eq!(new, Some(&20));
// 查询Yellow对应的值,若不存在则插入新值
let v = scores.entry("Yellow").or_insert(5);
assert_eq!(*v, 5); // 不存在,插入5
// 查询Yellow对应的值,若不存在则插入新值
let v = scores.entry("Yellow").or_insert(50);
assert_eq!(*v, 5); // 已经存在,因此50没有插入
}
哈希函数
你肯定比较好奇,为何叫哈希表,到底什么是哈希。
先来设想下,如果要实现 Key 与 Value 的一一对应,是不是意味着我们要能比较两个 Key 的相等性?例如 "a" 和 "b",1 和 2,当这些类型做 Key 且能比较时,可以很容易知道 1 对应的值不会错误的映射到 2 上,因为 1 不等于 2。因此,一个类型能否作为 Key 的关键就是是否能进行相等比较,或者说该类型是否实现了 std::cmp::Eq 特征。
f32 和 f64 浮点数,没有实现
std::cmp::Eq特征,因此不可以用作HashMap的Key。
好了,理解完这个,再来设想一点,若一个复杂点的类型作为 Key,那怎么在底层对它进行存储,怎么使用它进行查询和比较? 是不是很棘手?好在我们有哈希函数:通过它把 Key 计算后映射为哈希值,然后使用该哈希值来进行存储、查询、比较等操作。
但是问题又来了,如何保证不同 Key 通过哈希后的两个值不会相同?如果相同,那意味着我们使用不同的 Key,却查到了同一个结果,这种明显是错误的行为。 此时,就涉及到安全性跟性能的取舍了。
若要追求安全,尽可能减少冲突,同时防止拒绝服务(Denial of Service, DoS)攻击,就要使用密码学安全的哈希函数,HashMap 就是使用了这样的哈希函数。反之若要追求性能,就需要使用没有那么安全的算法。
高性能三方库
目前,HashMap 使用的哈希函数是 SipHash,它的性能不是很高,但是安全性很高。SipHash 在中等大小的 Key 上,性能相当不错,但是对于小型的 Key (例如整数)或者大型 Key (例如字符串)来说,性能还是不够好。若你需要极致性能,例如实现算法,可以考虑这个库:ahash。