目录
---------
这篇笔记实现主要是简单的 mustache.js,跟 vue 的模板语法相比,简单了许多(vue 的太难了,先从基础学起)
代码仓库:https://github.com/Plumbiu/vue_source_code
mustache
mustache 译为胡子,因为它的语法 {{}} 非常像胡子,官方地址:janl/mustache.js
{{}} 的语法也被 vue 沿用,可以说 mustache 是最早的模板引擎库,在当时的创造是非常有前瞻性的
基本使用
下面的示例是在 html 文件中使用的,我们首先要引入 mustache 库,可以在 bootcdn.com 中找到:
<ul>
{{#arr}}
<li>
<div class="hd">{{name}} 的基本信息</div>
<div class="bd">
<p>姓名:{{name}}</p>
<p>性别:{{sex}}</p>
<p>年龄:{{age}}</p>
</div>
</li>
{{/arr}}
</ul>
对应的 vue 语法:
<ul>
<li v-for="item in arr">
<div class="hd">{{item.name}} 的基本信息</div>
<div class="bd">
<p>姓名:{{item.name}}</p>
<p>性别:{{item.sex}}</p>
<p>年龄:{{item.age}}</p>
</div>
</li>
</ul>
具体使用
mustache 是基于模板字符串渲染视图的,也就是说我们必须有一个对应的字符串,为了使得逻辑更加清晰,我们可以使用 script 标签自带的模板属性:
<script type="text/template" id="mytemplate">
<ul>
{{#arr}}
<li>
<div class="hd">{{name}}的基本信息</div>
<div class="bd">
<p>姓名:{{name}}</p>
<p>性别:{{sex}}</p>
<p>年龄:{{age}}</p>
</div>
</li>
{{/arr}}
</ul>
</script>
想要获取上述 script 标签的模板,只需要 innerHTML 即可
<body>
<div id="container"></div>
</body>
<script>
// 先获取 dom 元素,再获取 innerHTML 模板字符串
const templateStr = document.getElementById('mytemplate').innerHTML
// 准备数据
const data = {
arr: [
{ name: 'xm', sex: '男', age: 18 },
{ name: 'xh', sex: '女', age: 19 },
{ name: 'xg', sex: '男', age: 20 }
]
}
// 使用 Mustache 获取 DOM 字符串
const domStr = Mustache.render(templateStr, data)
// 获取要渲染的 dom 元素容器
const container = document.getElementById('container')
// 将模板字符串插入
container.innerHTML = domStr
</script>
Mustache 不仅支持循环渲染,也支持一些基本渲染
- 单纯渲染字符串
const domStr = Mustache.render(`
<h1>我买了一个{{thing}},我好{{mood}}</h1>
`, { thing: '苹果手机', mood: '开心' })
- 渲染数组
const domStr = Mustache.render(`
<ul>
{{#arr}}
<li>{{.}}</li>
{{/arr}}
</ul>
`, { arr: ['hello', 'world', 'hello', 'mustache'] })
原理
我们可以使用简单的正则表达式,实现简单的模板替换:
// 1. 准备模板字符串
const templateStr = '<h1>我买了一个{{thing}},感到好{{mood}}'
// 2. 准备数据
const data = { thing: '苹果手机', mood: '开心' }
// 3. 正则匹配规则
const reg = /\{\{(\w+)\}\}/g
// 4. 转换函数
function render(template, values) {
return template.replace(reg, (find, capture, index, orginStr) => {
return data[capture]
})
}
// 5. 转换成 DOM 字符串
const domStr = render(templateStr, data)
字符串实例的
replace方法的第二个参数可以是一个函数,该函数共有四个参数(上述示例的正则表达式匹配{{}}内容):
find:表示匹配的字符串,上述示例对应{{thing}}和{{mood}}capture:表示捕获的字符串,上述示例对应capture则为thing和moodindex:捕获的字符串索引originStr:字符串实例
但实际上Mustache 并不是简单基于正则表达式,而是下图所示流程:

tokens其实就是一个 JS 的嵌套数组,它是AST 抽象语法树、虚拟节点等的开山鼻祖
所以 mustache 底层逻辑为:
- 将模板字符串编译为 tokens 形式
- 将 tokens 结合数据,解析为 dom 字符串
例如以下示例:
- 模板字符串
<h1>我买了一个{{thing}},好{{mood}}啊</h1>
tokens
tokens 是一个数组,其中每一项就是 token
[
["text", "<h1>我买了一个"],
["name", "thing"],
["text", ",好"],
["name", "mood"],
["text", "啊</h1>"]
]
当模板字符串有循环存在时,会被编译为嵌套更深的 tokens
- 模板字符串
<div>
<ul>
{{#arr}}
<li>{{.}}</li>
{{/arr}}
</ul>
</div>
tokens
[
["text": "<div><ul>"],
["#", "arr", [
["text", "<li>"],
["name", "."],
["text", "</li>"]
]],
["text", "</ul></div>"]
]
手写 mustache
模板字符串解析为 tokens
例如下面的模板字符串:
"<h1>我买了一个{{thing}},感觉好{{mood}}啊</h1>"
我们的流程是准备 scan 和 scanUtil 方法,作用如下:
scan:扫描{{和}}字符,并且过滤掉scanUtil:扫描到{{和}}字符停止,并返回从开始的位置到结束位置的字符串,作为token
首先我们需要一个全局方法 PlumbiuTemplateEngine,作为 mustache.js 的 Mustache.render 方法:
window.PlumbiuTemplateEngine = {
render(templateStr, data) {
// do something
}
}
render 函数中要做的事情有解析模板字符串,我们仿照官方定义一个 Scanner 扫描类:
class Scanner {
constructor(templateStr) {
// 将模板字符串写到实例上
this.templateStr = templateStr
// 指针
this.pos = 0
// 尾巴字符串,一开始是字符串原文
this.tail = templateStr
}
// scan 方法的功能较弱,只是扫描 tag,没有返回值
scan(tag) {
if(this.tail.indexOf(tag) == 0) {
// tag 有多长就让指针加多少,例如 {{ 长度为 2,那么就让指针长度加 2
this.pos += tag.length
this.tail = this.templateStr.substring(this.pos)
}
}
// 让指针扫描到指定的 stopTag 结束,并且返回路过的文字,这些文字就是 token
scanUtil(stopTag) {
// 记录执行 scanUtil 方法时候的 pos 值,用于截取 token 开始的位置
const pos_backup = this.pos
// 当未扫描到 stopTag 时,指针加 1,并且截取尾巴字符串
while(!this.eos() && this.tail.indexOf(stopTag) != 0) {
this.pos ++
this.tail = this.teplateStr.substring(this.pos)
}
// 返回 token 的文字部分
return this.templateStr.substring(pos_backup, this.pos)
},
// 用于判断当前指针是否大于模板字符串的长度,返回一个布尔值
eos() {
return this.pos >= this.templateStr.length
}
}
同时修改 PlumbiuTemplateEngine 全局方法:
window.PlumbiuTemplateEngine = {
render(templateStr, data) {
// 实例化一个扫描器,用来扫描传入的模板字符串
const scanner = new Scanner(templateStr)
// 当指针未到字符串末尾时,执行循环
while(!scanner.eos()) {
// 该方法返回的是 `}}` 或者 `字符串起始位置` 到 `{{` 或者 字符串末尾的字符串,也就是 token 的文字部分
let word = scanner.scanUtil('{{')
scanner.scan('{{')
console.log(word)
// 扫描到 }}
word = scanner.scanUtil('}}')
scanner.scan('}}')
console.log(word)
}
}
}
上述方法写好之后,我们调用 PlumbiuTemplateEngine.render 方法:
PlumbiuTemplateEngine.render('<h1>我买了一个{{thing}},感觉好{{mood}}啊</h1>')
浏览器控制台打印:
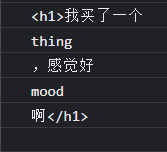
当然,最终结果应该是个数组,我们需要重新定义一个 parseTemplateToTokens 方法,用于将以上 token 片段合并到一个数组中
function parseTemplateToTokens(templateStr) {
const scanner = new Scanner(templateStr)
let tokens = []
let words
while(!scanner.eos()) {
// 扫描在 {{ 之前的文字,一定是 text
words = scanner.scanUtil('{{')
// 判断是否为空,为空不 push 进 tokens 数组中
if(words !== '') {
tokens.push(['text', words])
}
scanner.scan('}}')
// 由于上述代码,指针已经指在 {{ 的末尾,所以该方法扫描到 }} 之前的文字,一定是 name
words = scanner.scanUtil('}}')
// 同上,判断 words 是否为空
if(words !== '') {
// 循环模板开始标签 #
if(words[0] === '#') {
tokens.push(['#', words.substring(1)])
} else if(words[0] === '/') { // 循环模板结束标签
tokens.push(['/', words.substring(1)])
} else {
tokens.push(['name', words])
}
}
scanner.scan('}}')
}
return tokens
}
修改 render 方法
window.PlumbiuTemplateEngine = {
render(templateStr, data) {
const tokens = parseTemplateToTokens(templateStr)
cosole.log(tokens)
}
}
浏览器控制台打印效果:
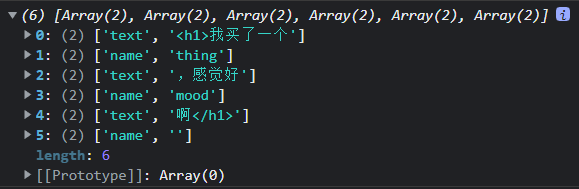
将嵌套的 tokens 嵌套起来
准备一个 nextTokens 方法,用于转换带有循环模板语法({{#arr}} {{/arr}})的模板字符串
首先我们定义一个空数组 nestedTokens,然后定义一个“收集器” collector 指向 nestedTokens
// 最终的结果数组
const nestedTokens = []
// 收集器,最初指向 nestedTokens,由于其引用类型,对 collector 的操作也会影响到 nestedTokens
// 收集器的指向会变,当遇到 # 时,收集器会指向这个 token 下标为 2 的项
let collector = nestedTokens
同时我们还需要指定一个栈结构,存放 token(tokens 的一项)
// 栈结构,存放 token 到栈顶(靠近端口,最新进入的)
const sections = []
转换的大致思路是:
- 遇到带有
#的token,将token放入collector和sections中,并改变collector收集器指向,指向当前token下标为 2 的项 - 遇到带有
/的项,将sections的栈顶一项pop出去,并将collector指向上一层sections或者nestedTokens
以下面模板字符串为例:(为了好展示,把空格和换行去掉)
`<ul>{{#student}}<div><li>{{name}}</li><ol>{{#hobby}}<li>{{.}}</li>{{/hobby}}</ol></div>{{/student}}</ul>`
浏览器打印:
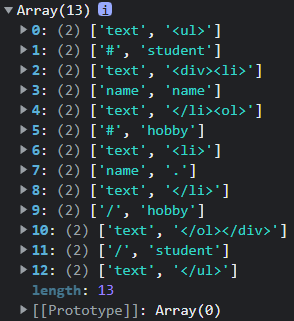
步骤
- 当未遍历到
‘#’或者/时,switch流程进入default语句,token加入collector - 当访问到
‘#’时,token加入到collector和sections中,同时collector指向token下标为 2 的数组 - 当访问到
‘/’时,sections做一次出栈操作,并将collector指向sections的上一级或者结果数组(nestedTokens) 中
关键的几个点:
-
sections指向带有#的token,作用是供collector指向第几层数组例如当读到
[‘#’, ‘student’]时:Javascriptsections = [['#', 'students']]读到
[‘#’, ‘hobby’]时:Javascriptsections = [['#', 'students'], ['#', 'hobby']] // 此时 collector 也会指向 ['#', 'hobby'] 数组下标索引为 2 的项 collector = token[2] = []当读到
[‘/’, ‘hobby’]时:Javascriptsections.pop() // sections = [['#', 'students']] // 同时使 collector 指向该项的第二项 collector = sections.length > 0 ? sections[sections.length - 1][2] : nestedTokens当读到
[‘/’, ‘student’]时:Javascriptsections.pop() // sections = [] // collector 指向 nestedTokens collector = sections.length > 0 ? sections[sections.length - 1][2] : nestedTokens -
js中的数据类型移至:
JS中的数据类型
lookup
mustache 中,会有 a.b.c 类似的模板字符串语法,而 js 对这种语法是不支持的
const obj = {
a: {
b: {
c: 1
}
}
}
console.log(obj['a.b.c']) // undefined
所以我们要手动实现能够处理这种语法的函数
function lookup(dataObj, keyName) {
// 如果 keyName 包括 . 并且 keyName 自身不等于 .
if(keyName.includes('.') && keyName !== '.') {
const keys = keyName.split('.')
let temp = dataObj
for(let i = 0; i < keys.length; i++) {
temp = temp[keys[i]]
}
return temp
}
// keyName 不包括 .
// 正常返回
return dataObj[keyName]
}
函数的具体思路是:
- 将类似
a.b.c的keyName,使用split(‘.’)方法,分隔成数组[‘a’, ‘b’, ‘c’] - 再利用
for循环依次返回对应的属性值,最后得到的便是dataObj.a.b.c
renderTemplate
renderTemplate 方法是将 tokens 转换为 DOM 字符串,该方法比较简单
function renderTemplate(tokens, data) {
let templateStr = ''
for(let i = 0; i < tokens.length; i++) {
let token = tokens[i]
if(token[0] === 'text') {
templateStr += token[1]
} else if(token[0] === 'name') { // Tip:由于存在类似 a.b.c 的写法,我们需要 lookup 函数处理
remplateStr += lookup(data, token[1])
} else if(token[0] === '#') {
// ...
}
}
return templateStr
}
parseArray
parseArray 方法主要处理 token[0] === ‘#’ 的情况:
function parseArray(token, data) {
// 由于 token[1] 可能是 a.b.c 的情况,所以使用 lookup 函数拿到真实的数据
const v = lookup(data, token[1)
// 结果字符串
let resultStr = ''
// 遍历 v 数组,这里考虑的情况都是简单情况,所以 v 一定是数组
for(let i = 0; i < v.length; i++) {
// 递归
// 由于 mustache 的数组渲染有 {{.}} 语法,所以要增添 '.' 键
result += renderTemplate(token[2], {
'.': v[i],
...v[i]
})
}
return resultStr
}
拿以下代码做示例:
const data = {
students: [
{ name: '小明', hobbies: ['游泳', '健身'] },
{ name: '小红', hobbies: ['足球', '篮球', '羽毛球'] },
{ name: '小强', hobbies: ['吃饭', '睡觉'] }
]
}
const templateStr = `
<div>
<ul class="uls">
{{#students}}
<li>
学生{{name}}的爱好是
<ol>
{{#hobbies}}
<li>{{.}}</li>
{{/hobbies}}
</ol>
</li>
{{/students}}
</ul>
</div>
`
打印的 tokens:
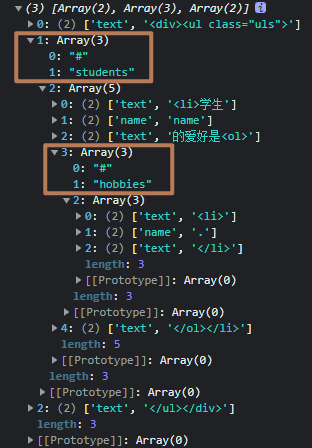
当遇到 token[0] 为 # 的时候,进入 parseArray 函数,parseArray 函数转换的步骤有:
- 先获取
data中对应的数据,例如上述代码为data[‘students’]和data[‘students’]中没一项的hobbies - 递归调用
renderTemplate,renderTemplate会对数组中每一项进行判断返回对应的 DOM 字符串。要注意的是要处理以下{{.}}语法,而{{.}}语法即渲染简单数组(例如['hello', 'world'])中的某一项。
去除 tokens 中的空格
用户在书写模板字符串时,为了方便阅读,往往会加许多空格和换行,我们需要去除这些空格,同时也要注意不要把标签内属性之间的空格去掉,例如 <li class="hd"></li> 就不能去除空格
修改 parseTemplateToTokens:
function parseTemplateToTokens(templateStr) {
let tokens = []
const scanner = new Scanner(templateStr)
let words
while(!scanner.eos()) {
// 收集开始标记前的文字
+ let isInJJH = false
// 空白字符串
let _words = ''
words = scanner.scanUtil('{{')
if(words !== '') {
// 存起来,去掉空格
+ for(let i = 0; i < words.length; i++) {
+ if(words[i] === '<') {
+ isInJJH = true
+ } else if(words[i] === '>') {
+ isInJJH = false
+ }
+ if(!words[i].match(/\s/g)) {
+ _words += words[i]
+ } else {
+ // 如果空格在标签内,那么才拼接上
+ if(isInJJH) {
+ _words += words[i]
+ }
+ }
+ }
+ tokens.push(['text', _words])
}
scanner.scan('{{')
}
处理思路:
- 定义一个 flag:
isInJJH用于判断是否在标签内 - 首先判断当前字符是否为
‘<’或‘>’,前者将isInJJH赋值为true,后者赋值为false
if(words[i] === '<') isInJJH = true
else if(words[i] === '>') isInJJH = false
- 判断当前字符是否为空格或者换行,如果不是,那么就加上这个字符;如果是,通过判断是否在标签内(即判断
isInJJH),为true才加上,否则不作任何处理
if(!words[i].match(/\s/g)) {
_words += words[i]
} else {
if(isInJJH) {
_words += words[i]
}
}